Client
Client is a handle to a YARN cluster to submit ApplicationMaster (that represents a Spark application submitted to a YARN cluster).
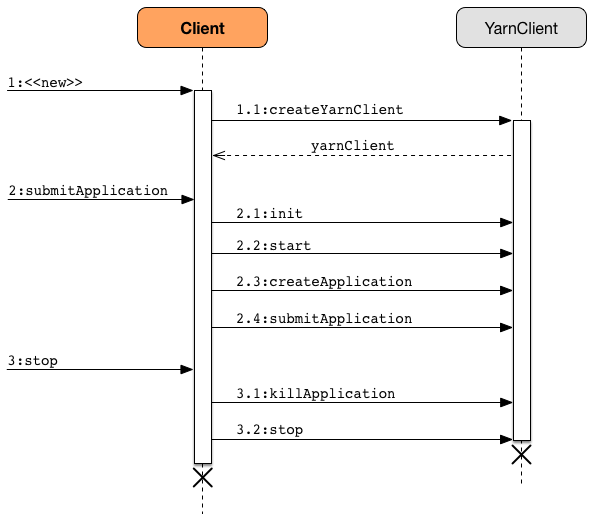
Figure 1. Client and Hadoop’s YarnClient Interactions
Depending on the deploy mode it uses ApplicationMaster or ApplicationMaster’s wrapper ExecutorLauncher by their class names in a ContainerLaunchContext (that represents all of the information needed by the YARN NodeManager to launch a container).
|
Note
|
Client was initially used as a standalone application to submit Spark applications to a YARN cluster, but is currently considered obsolete.
|
| Name | Initial Value | Description |
|---|---|---|
spark.yarn.executor.memoryOverhead and falls back to 10% of the spark.executor.memory or 384 whatever is larger. |
|
Tip
|
Enable Add the following line to Refer to Logging. |
isUserClassPathFirst Method
|
Caution
|
FIXME |
getUserClasspath Method
|
Caution
|
FIXME |
ClientArguments
|
Caution
|
FIXME |
Setting Up Environment to Launch ApplicationMaster Container — setupLaunchEnv Method
|
Caution
|
FIXME |
launcherBackend Property
launcherBackend…FIXME
loginFromKeytab Method
|
Caution
|
FIXME |
Creating Client Instance
Creating an instance of Client does the following:
-
Creates an internal instance of
YarnClient(usingYarnClient.createYarnClient) that becomesyarnClient. -
Creates an internal instance of
YarnConfiguration(usingYarnConfigurationand the inputhadoopConf) that becomesyarnConf. -
Sets the internal
isClusterModethat says whether spark.submit.deployMode is cluster deploy mode.
-
Sets the internal
amMemoryto spark.driver.memory whenisClusterModeis enabled or spark.yarn.am.memory otherwise. -
Sets the internal
amMemoryOverheadto spark.yarn.driver.memoryOverhead whenisClusterModeis enabled or spark.yarn.am.memoryOverhead otherwise. If neither is available, the maximum of 10% ofamMemoryand384is chosen. -
Sets the internal
amCoresto spark.driver.cores whenisClusterModeis enabled or spark.yarn.am.cores otherwise. -
Sets the internal
executorMemoryto spark.executor.memory. -
Sets the internal executorMemoryOverhead to spark.yarn.executor.memoryOverhead. If unavailable, it is set to the maximum of 10% of
executorMemoryand384. -
Creates an internal instance of ClientDistributedCacheManager (as
distCacheMgr). -
Sets the variables:
loginFromKeytabtofalsewithprincipal,keytab, andcredentialstonull. -
Creates an internal instance of
LauncherBackend(as launcherBackend). -
Sets the internal
fireAndForgetflag to the result ofisClusterModeand not spark.yarn.submit.waitAppCompletion. -
Sets the internal variable
appIdtonull. -
Sets the internal
appStagingBaseDirto spark.yarn.stagingDir or the home directory of Hadoop.
Submitting Spark Application to YARN — submitApplication Method
submitApplication(): ApplicationIdsubmitApplication submits a Spark application (represented by ApplicationMaster) to a YARN cluster (i.e. to the YARN ResourceManager) and returns the application’s ApplicationId.
|
Note
|
submitApplication is also used in the currently-deprecated Client.run.
|
Internally, it executes LauncherBackend.connect first and then executes Client.setupCredentials to set up credentials for future calls.
It then inits the internal yarnClient (with the internal yarnConf) and starts it. All this happens using Hadoop API.
|
Caution
|
FIXME How to configure YarnClient? What is YARN’s YarnClient.getYarnClusterMetrics?
|
You should see the following INFO in the logs:
INFO Client: Requesting a new application from cluster with [count] NodeManagersIt then YarnClient.createApplication() to create a new application in YARN and obtains the application id.
The LauncherBackend instance changes state to SUBMITTED with the application id.
|
Caution
|
FIXME Why is this important? |
submitApplication verifies whether the cluster has resources for the ApplicationManager (using verifyClusterResources).
It then creates YARN ContainerLaunchContext followed by creating YARN ApplicationSubmissionContext.
You should see the following INFO message in the logs:
INFO Client: Submitting application [appId] to ResourceManagersubmitApplication submits the new YARN ApplicationSubmissionContext for ApplicationMaster to YARN (using Hadoop’s YarnClient.submitApplication).
It returns the YARN ApplicationId for the Spark application (represented by ApplicationMaster).
|
Note
|
submitApplication is used when Client runs or YarnClientSchedulerBackend is started.
|
Creating YARN ApplicationSubmissionContext — createApplicationSubmissionContext Method
createApplicationSubmissionContext(
newApp: YarnClientApplication,
containerContext: ContainerLaunchContext): ApplicationSubmissionContextcreateApplicationSubmissionContext creates YARN’s ApplicationSubmissionContext.
|
Note
|
YARN’s ApplicationSubmissionContext represents all of the information needed by the YARN ResourceManager to launch the ApplicationMaster for a Spark application.
|
createApplicationSubmissionContext uses YARN’s YarnClientApplication (as the input newApp) to create a ApplicationSubmissionContext.
createApplicationSubmissionContext sets the following information in the ApplicationSubmissionContext:
The name of the Spark application |
spark.app.name configuration setting or |
Queue (to which the Spark application is submitted) |
spark.yarn.queue configuration setting |
|
the input |
Type of the Spark application |
|
Tags for the Spark application |
spark.yarn.tags configuration setting |
Number of max attempts of the Spark application to be submitted. |
spark.yarn.maxAppAttempts configuration setting |
The |
spark.yarn.am.attemptFailuresValidityInterval configuration setting |
Resource Capabilities for ApplicationMaster for the Spark application |
See Resource Capabilities for ApplicationMaster — Memory and Virtual CPU Cores section below |
Rolled Log Aggregation for the Spark application |
See Rolled Log Aggregation Configuration for Spark Application section below |
You will see the DEBUG message in the logs when the setting is not set:
DEBUG spark.yarn.maxAppAttempts is not set. Cluster's default value will be used.Resource Capabilities for ApplicationMaster — Memory and Virtual CPU Cores
|
Note
|
YARN’s Resource models a set of computer resources in the cluster. Currently, YARN supports resources with memory and virtual CPU cores capabilities only. |
The requested YARN’s Resource for the ApplicationMaster for a Spark application is the sum of amMemory and amMemoryOverhead for the memory and amCores for the virtual CPU cores.
Besides, if spark.yarn.am.nodeLabelExpression is set, a new YARN ResourceRequest is created (for the ApplicationMaster container) that includes:
Resource Name |
|
Priority |
|
Capability |
The resource capabilities as defined above. |
Number of containers |
|
Node label expression |
spark.yarn.am.nodeLabelExpression configuration setting |
ResourceRequest of AM container |
spark.yarn.am.nodeLabelExpression configuration setting |
It sets the resource request to this new YARN ResourceRequest detailed in the table above.
Rolled Log Aggregation for Spark Application
|
Note
|
YARN’s LogAggregationContext represents all of the information needed by the YARN NodeManager to handle the logs for an application. |
If spark.yarn.rolledLog.includePattern is defined, it creates a YARN LogAggregationContext with the following patterns:
Include Pattern |
spark.yarn.rolledLog.includePattern configuration setting |
Exclude Pattern |
spark.yarn.rolledLog.excludePattern configuration setting |
Verifying Maximum Memory Capability of YARN Cluster — verifyClusterResources Internal Method
verifyClusterResources(newAppResponse: GetNewApplicationResponse): UnitverifyClusterResources is a private helper method that submitApplication uses to ensure that the Spark application (as a set of ApplicationMaster and executors) is not going to request more than the maximum memory capability of the YARN cluster. If so, it throws an IllegalArgumentException.
verifyClusterResources queries the input GetNewApplicationResponse (as newAppResponse) for the maximum memory.
INFO Client: Verifying our application has not requested more than the maximum memory capability of the cluster ([maximumMemory] MB per container)
If the maximum memory capability is above the required executor or ApplicationMaster memory, you should see the following INFO message in the logs:
INFO Client: Will allocate AM container, with [amMem] MB memory including [amMemoryOverhead] MB overhead
If however the executor memory (as a sum of spark.executor.memory and spark.yarn.executor.memoryOverhead settings) is more than the maximum memory capability, verifyClusterResources throws an IllegalArgumentException with the following message:
Required executor memory ([executorMemory]+[executorMemoryOverhead] MB) is above the max threshold ([maximumMemory] MB) of this cluster! Please check the values of 'yarn.scheduler.maximum-allocation-mb' and/or 'yarn.nodemanager.resource.memory-mb'.
If the required memory for ApplicationMaster is more than the maximum memory capability, verifyClusterResources throws an IllegalArgumentException with the following message:
Required AM memory ([amMemory]+[amMemoryOverhead] MB) is above the max threshold ([maximumMemory] MB) of this cluster! Please increase the value of 'yarn.scheduler.maximum-allocation-mb'.
Creating YARN ContainerLaunchContext to Launch ApplicationMaster — createContainerLaunchContext Internal Method
createContainerLaunchContext(newAppResponse: GetNewApplicationResponse): ContainerLaunchContext|
Note
|
The input GetNewApplicationResponse is Hadoop YARN’s GetNewApplicationResponse.
|
When a Spark application is submitted to YARN, it calls the private helper method createContainerLaunchContext that creates a YARN ContainerLaunchContext request for YARN NodeManager to launch ApplicationMaster (in a container).
When called, you should see the following INFO message in the logs:
INFO Setting up container launch context for our AMIt gets at the application id (from the input newAppResponse).
It calculates the path of the application’s staging directory.
|
Caution
|
FIXME What’s appStagingBaseDir?
|
It does a custom step for a Python application.
It sets up an environment to launch ApplicationMaster container and prepareLocalResources. A ContainerLaunchContext record is created with the environment and the local resources.
The JVM options are calculated as follows:
-
-Xmx(that was calculated when the Client was created) -
-Djava.io.tmpdir=- FIXME:tmpDirCautionFIXME tmpDir? -
Using
UseConcMarkSweepGCwhenSPARK_USE_CONC_INCR_GCis enabled.CautionFIXME SPARK_USE_CONC_INCR_GC? -
In cluster deploy mode, …FIXME
-
In client deploy mode, …FIXME
CautionFIXME -
-Dspark.yarn.app.container.log.dir=…FIXME -
Perm gen size option…FIXME
--class is set if in cluster mode based on --class command-line argument.
|
Caution
|
FIXME |
If --jar command-line argument was specified, it is set as --jar.
In cluster deploy mode, org.apache.spark.deploy.yarn.ApplicationMaster is created while in client deploy mode it is org.apache.spark.deploy.yarn.ExecutorLauncher.
If --arg command-line argument was specified, it is set as --arg.
The path for --properties-file is built based on YarnSparkHadoopUtil.expandEnvironment(Environment.PWD), LOCALIZED_CONF_DIR, SPARK_CONF_FILE.
The entire ApplicationMaster argument line (as amArgs) is of the form:
[amClassName] --class [userClass] --jar [userJar] --arg [userArgs] --properties-file [propFile]The entire command line is of the form:
|
Caution
|
FIXME prefixEnv? How is path calculated? ApplicationConstants.LOG_DIR_EXPANSION_VAR?
|
[JAVA_HOME]/bin/java -server [javaOpts] [amArgs] 1> [LOG_DIR]/stdout 2> [LOG_DIR]/stderrThe command line to launch a ApplicationMaster is set to the ContainerLaunchContext record (using setCommands).
You should see the following DEBUG messages in the logs:
DEBUG Client: ===============================================================================
DEBUG Client: YARN AM launch context:
DEBUG Client: user class: N/A
DEBUG Client: env:
DEBUG Client: [launchEnv]
DEBUG Client: resources:
DEBUG Client: [localResources]
DEBUG Client: command:
DEBUG Client: [commands]
DEBUG Client: ===============================================================================A SecurityManager is created and set as the application’s ACLs.
|
Caution
|
FIXME setApplicationACLs? Set up security tokens?
|
|
Note
|
createContainerLaunchContext is used when Client submits a Spark application to a YARN cluster.
|
prepareLocalResources Method
|
Caution
|
FIXME |
prepareLocalResources(
destDir: Path,
pySparkArchives: Seq[String]): HashMap[String, LocalResource]prepareLocalResources is…FIXME
|
Caution
|
FIXME Describe credentialManager
|
When called, prepareLocalResources prints out the following INFO message to the logs:
INFO Client: Preparing resources for our AM container|
Caution
|
FIXME What’s a delegation token? |
prepareLocalResources then obtains security tokens from credential providers and gets the nearest time of the next renewal (for renewable credentials).
After all the security delegation tokens are obtained and only when there are any, you should see the following DEBUG message in the logs:
DEBUG Client: [token1]
DEBUG Client: [token2]
...
DEBUG Client: [tokenN]|
Caution
|
FIXME Where is credentials assigned?
|
If a keytab is used to log in and the nearest time of the next renewal is in the future, prepareLocalResources sets the internal spark.yarn.credentials.renewalTime and spark.yarn.credentials.updateTime times for renewal and update security tokens.
It gets the replication factor (using spark.yarn.submit.file.replication setting) or falls back to the default value for the input destDir.
|
Note
|
The replication factor is only used for copyFileToRemote later. Perhaps it should not be mentioned here (?) |
It creates the input destDir (on a HDFS-compatible file system) with 0700 permission (rwx------), i.e. inaccessible to all but its owner and the superuser so the owner only can read, write and execute. It uses Hadoop’s Path.getFileSystem to access Hadoop’s FileSystem that owns destDir (using the constructor’s hadoopConf — Hadoop’s Configuration).
|
Tip
|
See org.apache.hadoop.fs.FileSystem to know a list of HDFS-compatible file systems, e.g. Amazon S3 or Windows Azure. |
|
Caution
|
FIXME if (loginFromKeytab)
|
If the location of the single archive containing Spark jars (spark.yarn.archive) is set, it is distributed (as ARCHIVE) to spark_libs.
Else if the location of the Spark jars (spark.yarn.jars) is set, …FIXME
|
Caution
|
FIXME Describe case Some(jars)
|
If neither spark.yarn.archive nor spark.yarn.jars is set, you should see the following WARN message in the logs:
WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.It then finds the directory with jar files under SPARK_HOME (using YarnCommandBuilderUtils.findJarsDir).
|
Caution
|
FIXME YarnCommandBuilderUtils.findJarsDir
|
And all the jars are zipped to a temporary archive, e.g. spark_libs2944590295025097383.zip that is distribute as ARCHIVE to spark_libs (only when they differ).
If a user jar (--jar) was specified on command line, the jar is distribute as FILE to app.jar.
It then distributes additional resources specified in SparkConf for the application, i.e. jars (under spark.yarn.dist.jars), files (under spark.yarn.dist.files), and archives (under spark.yarn.dist.archives).
|
Note
|
The additional files to distribute can be defined using spark-submit using command-line options --jars, --files, and --archives. |
|
Caution
|
FIXME Describe distribute
|
It sets spark.yarn.secondary.jars for the jars that have localized path (non-local paths) or their path (for local paths).
It updates Spark configuration (with internal configuration settings using the internal distCacheMgr reference).
|
Caution
|
FIXME Where are they used? It appears they are required for ApplicationMaster when it prepares local resources, but what is the sequence of calls to lead to ApplicationMaster?
|
It uploads spark_conf.zip to the input destDir and sets spark.yarn.cache.confArchive
It creates configuration archive and copyFileToRemote(destDir, localConfArchive, replication, force = true, destName = Some(LOCALIZED_CONF_ARCHIVE)).
|
Caution
|
FIXME copyFileToRemote(destDir, localConfArchive, replication, force = true, destName = Some(LOCALIZED_CONF_ARCHIVE))?
|
It adds a cache-related resource (using the internal distCacheMgr).
|
Caution
|
FIXME What resources? Where? Why is this needed? |
Ultimately, it clears the cache-related internal configuration settings — spark.yarn.cache.filenames, spark.yarn.cache.sizes, spark.yarn.cache.timestamps, spark.yarn.cache.visibilities, spark.yarn.cache.types, spark.yarn.cache.confArchive — from the SparkConf configuration since they are internal and should not "pollute" the web UI’s environment page.
The localResources are returned.
|
Caution
|
FIXME How is localResources calculated?
|
|
Note
|
It is exclusively used when Client creates a ContainerLaunchContext to launch a ApplicationMaster container.
|
Creating __spark_conf__.zip Archive With Configuration Files and Spark Configuration — createConfArchive Internal Method
createConfArchive(): FilecreateConfArchive is a private helper method that prepareLocalResources uses to create an archive with the local config files — log4j.properties and metrics.properties (before distributing it and the other files for ApplicationMaster and executors to use on a YARN cluster).
The archive will also contain all the files under HADOOP_CONF_DIR and YARN_CONF_DIR environment variables (if defined).
Additionally, the archive contains a spark_conf.properties with the current Spark configuration.
The archive is a temporary file with the spark_conf prefix and .zip extension with the files above.
Copying File to Remote File System — copyFileToRemote Method
copyFileToRemote(
destDir: Path,
srcPath: Path,
replication: Short,
force: Boolean = false,
destName: Option[String] = None): PathcopyFileToRemote is a private[yarn] method to copy srcPath to the remote file system destDir (if needed) and return the destination path resolved following symlinks and mount points.
|
Note
|
It is exclusively used in prepareLocalResources. |
Unless force is enabled (it is disabled by default), copyFileToRemote will only copy srcPath when the source (of srcPath) and target (of destDir) file systems are the same.
You should see the following INFO message in the logs:
INFO Client: Uploading resource [srcPath] -> [destPath]copyFileToRemote copies srcPath to destDir and sets 644 permissions, i.e. world-wide readable and owner writable.
If force is disabled or the files are the same, copyFileToRemote will only print out the following INFO message to the logs:
INFO Client: Source and destination file systems are the same. Not copying [srcPath]Ultimately, copyFileToRemote returns the destination path resolved following symlinks and mount points.
Populating CLASSPATH for ApplicationMaster and Executors — populateClasspath Method
populateClasspath(
args: ClientArguments,
conf: Configuration,
sparkConf: SparkConf,
env: HashMap[String, String],
extraClassPath: Option[String] = None): UnitpopulateClasspath is a private[yarn] helper method that populates the CLASSPATH (for ApplicationMaster and executors).
|
Note
|
The input args is null when preparing environment for ExecutorRunnable and the constructor’s args for Client.
|
-
The optional
extraClassPath(which is first changed to include paths on YARN cluster machines).NoteextraClassPathcorresponds to spark.driver.extraClassPath for the driver and spark.executor.extraClassPath for executors. -
YARN’s own
Environment.PWD -
__spark_conf__directory under YARN’sEnvironment.PWD -
If the deprecated spark.yarn.user.classpath.first is set, …FIXME
CautionFIXME -
__spark_libs__/*under YARN’sEnvironment.PWD -
(unless the optional spark.yarn.archive is defined) All the
localjars in spark.yarn.jars (which are first changed to be paths on YARN cluster machines). -
All the entries from YARN’s
yarn.application.classpathorYarnConfiguration.DEFAULT_YARN_APPLICATION_CLASSPATH(ifyarn.application.classpathis not set) -
All the entries from YARN’s
mapreduce.application.classpathorMRJobConfig.DEFAULT_MAPREDUCE_APPLICATION_CLASSPATH(ifmapreduce.application.classpathnot set). -
SPARK_DIST_CLASSPATH (which is first changed to include paths on YARN cluster machines).
|
Tip
|
You should see the result of executing |
Changing Path to be YARN NodeManager-aware — getClusterPath Method
getClusterPath(conf: SparkConf, path: String): StringgetClusterPath replaces any occurences of spark.yarn.config.gatewayPath in path to the value of spark.yarn.config.replacementPath.
Adding CLASSPATH Entry to Environment — addClasspathEntry Method
addClasspathEntry(path: String, env: HashMap[String, String]): UnitaddClasspathEntry is a private helper method to add the input path to CLASSPATH key in the input env.
Distributing Files to Remote File System — distribute Internal Method
distribute(
path: String,
resType: LocalResourceType = LocalResourceType.FILE,
destName: Option[String] = None,
targetDir: Option[String] = None,
appMasterOnly: Boolean = false): (Boolean, String)distribute is an internal helper method that prepareLocalResources uses to find out whether the input path is of local: URI scheme and return a localized path for a non-local path, or simply the input path for a local one.
distribute returns a pair with the first element being a flag for the input path being local or non-local, and the other element for the local or localized path.
For local path that was not distributed already, distribute copies the input path to remote file system (if needed) and adds path to the application’s distributed cache.
Joining Path Components using Path.SEPARATOR — buildPath Method
buildPath(components: String*): StringbuildPath is a helper method to join all the path components using the directory separator, i.e. org.apache.hadoop.fs.Path.SEPARATOR.
isClusterMode Internal Flag
isClusterMode is an internal flag that says whether the Spark application runs in cluster or client deploy mode. The flag is enabled for cluster deploy mode, i.e. true.
|
Note
|
Since a Spark application requires different settings per deploy mode, isClusterMode flag effectively "splits" Client on two parts per deploy mode — one responsible for client and the other for cluster deploy mode.
|
|
Caution
|
FIXME Replace the internal fields used below with their true meanings. |
| Internal attribute | cluster deploy mode | client deploy mode |
|---|---|---|
|
||
|
||
|
||
|
||
|
||
|
||
Application master class |
When the isClusterMode flag is enabled, the internal reference to YARN’s YarnClient is used to stop application.
When the isClusterMode flag is enabled (and spark.yarn.submit.waitAppCompletion is disabled), so is fireAndForget internal flag.
SPARK_YARN_MODE flag
SPARK_YARN_MODE flag controls…FIXME
|
Note
|
Any environment variable with the SPARK_ prefix is propagated to all (remote) processes.
|
|
Caution
|
FIXME Where is SPARK_ prefix rule enforced?
|
|
Note
|
SPARK_YARN_MODE is a system property (i.e. available using System.getProperty) and a environment variable (i.e. available using System.getenv or sys.env). See YarnSparkHadoopUtil.
|
It is enabled (i.e. true) when SparkContext is created for Spark on YARN in client deploy mode, when Client sets up an environment to launch ApplicationMaster container (and, what is currently considered deprecated, a Spark application was deployed to a YARN cluster).
|
Caution
|
FIXME Why is this needed? git blame it.
|
SPARK_YARN_MODE flag is checked when YarnSparkHadoopUtil or SparkHadoopUtil are accessed.
It is cleared later when Client is requested to stop.
Internal Hadoop’s YarnClient — yarnClient Property
val yarnClient = YarnClient.createYarnClientyarnClient is a private internal reference to Hadoop’s YarnClient that Client uses to create and submit a YARN application (for your Spark application), killApplication.
yarnClient is inited and started when Client submits a Spark application to a YARN cluster.
yarnClient is stopped when Client stops.
Launching Client Standalone Application — main Method
main method is invoked while a Spark application is being deployed to a YARN cluster.
|
Note
|
It is executed by spark-submit with --master yarn command-line argument.
|
|
Note
|
When you start the |
main turns SPARK_YARN_MODE flag on.
It then instantiates SparkConf, parses command-line arguments (using ClientArguments) and passes the call on to Client.run method.
Stopping Client (with LauncherBackend and YarnClient) — stop Method
stop(): Unitstop closes the internal LauncherBackend and stops the internal YarnClient.
It also clears SPARK_YARN_MODE flag (to allow switching between cluster types).
Running Client — run Method
run submits a Spark application to a YARN ResourceManager (RM).
If LauncherBackend is not connected to a RM, i.e. LauncherBackend.isConnected returns false, and fireAndForget is enabled, …FIXME
|
Caution
|
FIXME When could LauncherBackend lost the connection since it was connected in submitApplication?
|
|
Caution
|
FIXME What is fireAndForget?
|
Otherwise, when LauncherBackend is connected or fireAndForget is disabled, monitorApplication is called. It returns a pair of yarnApplicationState and finalApplicationStatus that is checked against three different state pairs and throw a SparkException:
-
YarnApplicationState.KILLEDorFinalApplicationStatus.KILLEDlead toSparkExceptionwith the message "Application [appId] is killed". -
YarnApplicationState.FAILEDorFinalApplicationStatus.FAILEDlead toSparkExceptionwith the message "Application [appId] finished with failed status". -
FinalApplicationStatus.UNDEFINEDleads toSparkExceptionwith the message "The final status of application [appId] is undefined".
|
Caution
|
FIXME What are YarnApplicationState and FinalApplicationStatus statuses?
|
monitorApplication Method
monitorApplication(
appId: ApplicationId,
returnOnRunning: Boolean = false,
logApplicationReport: Boolean = true): (YarnApplicationState, FinalApplicationStatus)monitorApplication continuously reports the status of a Spark application appId every spark.yarn.report.interval until the application state is one of the following YarnApplicationState:
-
RUNNING(whenreturnOnRunningis enabled) -
FINISHED -
FAILED -
KILLED
|
Note
|
It is used in run, YarnClientSchedulerBackend.waitForApplication and MonitorThread.run.
|
It gets the application’s report from the YARN ResourceManager to obtain YarnApplicationState of the ApplicationMaster.
|
Tip
|
It uses Hadoop’s YarnClient.getApplicationReport(appId).
|
Unless logApplicationReport is disabled, it prints the following INFO message to the logs:
INFO Client: Application report for [appId] (state: [state])If logApplicationReport and DEBUG log level are enabled, it prints report details every time interval to the logs:
16/04/23 13:21:36 INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1461410495109
final status: UNDEFINED
tracking URL: http://japila.local:8088/proxy/application_1461410200840_0001/
user: jacekFor INFO log level it prints report details only when the application state changes.
When the application state changes, LauncherBackend is notified (using LauncherBackend.setState).
|
Note
|
The application state is an instance of Hadoop’s YarnApplicationState.
|
For states FINISHED, FAILED or KILLED, cleanupStagingDir is called and the method finishes by returning a pair of the current state and the final application status.
If returnOnRunning is enabled (it is disabled by default) and the application state turns RUNNING, the method returns a pair of the current state RUNNING and the final application status.
|
Note
|
cleanupStagingDir won’t be called when returnOnRunning is enabled and an application turns RUNNING. I guess it is likely a left-over since the Client is deprecated now.
|
The current state is recorded for future checks (in the loop).
cleanupStagingDir Method
cleanupStagingDir clears the staging directory of an application.
|
Note
|
It is used in submitApplication when there is an exception and monitorApplication when an application finishes and the method quits. |
It uses spark.yarn.stagingDir setting or falls back to a user’s home directory for the staging directory. If cleanup is enabled, it deletes the entire staging directory for the application.
You should see the following INFO message in the logs:
INFO Deleting staging directory [stagingDirPath]