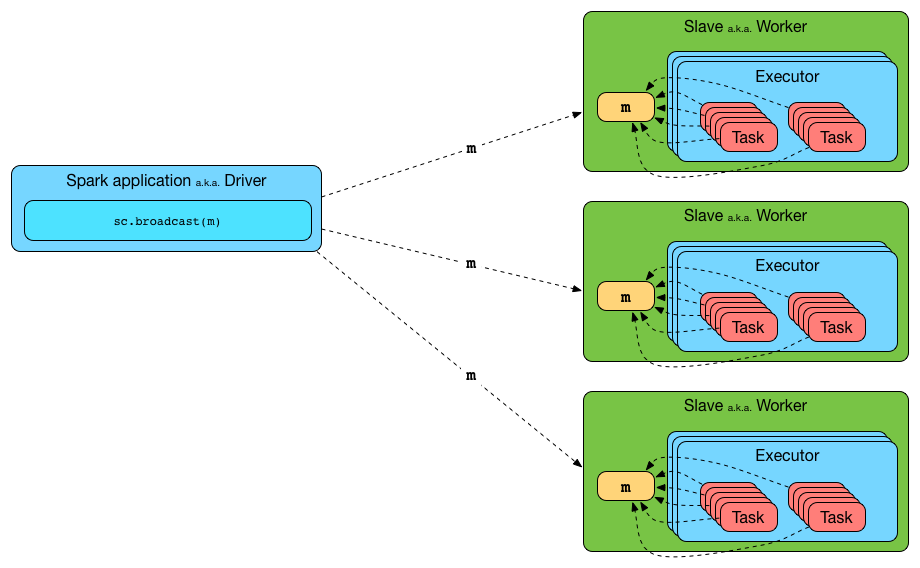
Broadcast Variables
Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks.
And later in the document:
Explicitly creating broadcast variables is only useful when tasks across multiple stages need the same data or when caching the data in deserialized form is important.
Figure 1. Broadcasting a value to executors
To use a broadcast value in a Spark transformation you have to create it first using SparkContext.broadcast and then use value method to access the shared value. Learn it in Introductory Example section.
The Broadcast feature in Spark uses SparkContext to create broadcast values and BroadcastManager and ContextCleaner to manage their lifecycle.
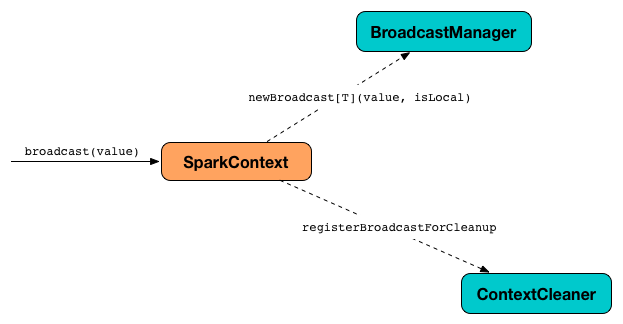
Figure 2. SparkContext to broadcast using BroadcastManager and ContextCleaner
|
Tip
|
Not only can Spark developers use broadcast variables for efficient data distribution, but Spark itself uses them quite often. A very notable use case is when Spark distributes tasks to executors for their execution. That does change my perspective on the role of broadcast variables in Spark. |
Broadcast Spark Developer-Facing Contract
The developer-facing Broadcast contract allows Spark developers to use it in their applications.
| Method Name | Description |
|---|---|
|
The unique identifier |
The value |
|
Asynchronously deletes cached copies of this broadcast on the executors. |
|
Destroys all data and metadata related to this broadcast variable. |
|
|
The string representation |
Lifecycle of Broadcast Variable
You can create a broadcast variable of type T using SparkContext.broadcast method.
scala> val b = sc.broadcast(1)
b: org.apache.spark.broadcast.Broadcast[Int] = Broadcast(0)|
Tip
|
Enable Read BlockManager to find out how to enable the logging level. |
With DEBUG logging level enabled, you should see the following messages in the logs:
DEBUG BlockManager: Put block broadcast_0 locally took 430 ms
DEBUG BlockManager: Putting block broadcast_0 without replication took 431 ms
DEBUG BlockManager: Told master about block broadcast_0_piece0
DEBUG BlockManager: Put block broadcast_0_piece0 locally took 4 ms
DEBUG BlockManager: Putting block broadcast_0_piece0 without replication took 4 msAfter creating an instance of a broadcast variable, you can then reference the value using value method.
scala> b.value
res0: Int = 1|
Note
|
value method is the only way to access the value of a broadcast variable.
|
With DEBUG logging level enabled, you should see the following messages in the logs:
DEBUG BlockManager: Getting local block broadcast_0
DEBUG BlockManager: Level for block broadcast_0 is StorageLevel(disk, memory, deserialized, 1 replicas)When you are done with a broadcast variable, you should destroy it to release memory.
scala> b.destroyWith DEBUG logging level enabled, you should see the following messages in the logs:
DEBUG BlockManager: Removing broadcast 0
DEBUG BlockManager: Removing block broadcast_0_piece0
DEBUG BlockManager: Told master about block broadcast_0_piece0
DEBUG BlockManager: Removing block broadcast_0Before destroying a broadcast variable, you may want to unpersist it.
scala> b.unpersist Getting the Value of Broadcast Variable — value Method
value: Tvalue returns the value of a broadcast variable. You can only access the value until it is destroyed after which you will see the following SparkException exception in the logs:
org.apache.spark.SparkException: Attempted to use Broadcast(0) after it was destroyed (destroy at <console>:27)
at org.apache.spark.broadcast.Broadcast.assertValid(Broadcast.scala:144)
at org.apache.spark.broadcast.Broadcast.value(Broadcast.scala:69)
... 48 elidedInternally, value makes sure that the broadcast variable is valid, i.e. destroy was not called, and, if so, calls the abstract getValue method.
|
Note
|
Refer to TorrentBroadcast. |
Unpersisting Broadcast Variable — unpersist Methods
unpersist(): Unit
unpersist(blocking: Boolean): Unit Destroying Broadcast Variable — destroy Method
destroy(): Unitdestroy removes a broadcast variable.
|
Note
|
Once a broadcast variable has been destroyed, it cannot be used again. |
If you try to destroy a broadcast variable more than once, you will see the following SparkException exception in the logs:
scala> b.destroy
org.apache.spark.SparkException: Attempted to use Broadcast(0) after it was destroyed (destroy at <console>:27)
at org.apache.spark.broadcast.Broadcast.assertValid(Broadcast.scala:144)
at org.apache.spark.broadcast.Broadcast.destroy(Broadcast.scala:107)
at org.apache.spark.broadcast.Broadcast.destroy(Broadcast.scala:98)
... 48 elidedInternally, destroy executes the internal destroy (with blocking enabled).
Removing Persisted Data of Broadcast Variable — destroy Internal Method
destroy(blocking: Boolean): Unitdestroy destroys all data and metadata of a broadcast variable.
|
Note
|
destroy is a private[spark] method.
|
Internally, destroy marks a broadcast variable destroyed, i.e. the internal _isValid flag is disabled.
You should see the following INFO message in the logs:
INFO TorrentBroadcast: Destroying Broadcast([id]) (from [destroySite])In the end, doDestroy method is executed (that broadcast implementations are supposed to provide).
|
Note
|
doDestroy is a part of the Broadcast contract for broadcast implementations so they can provide their own custom behaviour.
|
Introductory Example
Let’s start with an introductory example to check out how to use broadcast variables and build your initial understanding.
You’re going to use a static mapping of interesting projects with their websites, i.e. Map[String, String] that the tasks, i.e. closures (anonymous functions) in transformations, use.
scala> val pws = Map("Apache Spark" -> "http://spark.apache.org/", "Scala" -> "http://www.scala-lang.org/")
pws: scala.collection.immutable.Map[String,String] = Map(Apache Spark -> http://spark.apache.org/, Scala -> http://www.scala-lang.org/)
scala> val websites = sc.parallelize(Seq("Apache Spark", "Scala")).map(pws).collect
...
websites: Array[String] = Array(http://spark.apache.org/, http://www.scala-lang.org/)It works, but is very ineffective as the pws map is sent over the wire to executors while it could have been there already. If there were more tasks that need the pws map, you could improve their performance by minimizing the number of bytes that are going to be sent over the network for task execution.
Enter broadcast variables.
val pwsB = sc.broadcast(pws)
val websites = sc.parallelize(Seq("Apache Spark", "Scala")).map(pwsB.value).collect
// websites: Array[String] = Array(http://spark.apache.org/, http://www.scala-lang.org/)Semantically, the two computations - with and without the broadcast value - are exactly the same, but the broadcast-based one wins performance-wise when there are more executors spawned to execute many tasks that use pws map.
Introduction
Broadcast is part of Spark that is responsible for broadcasting information across nodes in a cluster.
You use broadcast variable to implement map-side join, i.e. a join using a map. For this, lookup tables are distributed across nodes in a cluster using broadcast and then looked up inside map (to do the join implicitly).
When you broadcast a value, it is copied to executors only once (while it is copied multiple times for tasks otherwise). It means that broadcast can help to get your Spark application faster if you have a large value to use in tasks or there are more tasks than executors.
It appears that a Spark idiom emerges that uses broadcast with collectAsMap to create a Map for broadcast. When an RDD is map over to a smaller dataset (column-wise not record-wise), collectAsMap, and broadcast, using the very big RDD to map its elements to the broadcast RDDs is computationally faster.
val acMap = sc.broadcast(myRDD.map { case (a,b,c,b) => (a, c) }.collectAsMap)
val otherMap = sc.broadcast(myOtherRDD.collectAsMap)
myBigRDD.map { case (a, b, c, d) =>
(acMap.value.get(a).get, otherMap.value.get(c).get)
}.collectUse large broadcasted HashMaps over RDDs whenever possible and leave RDDs with a key to lookup necessary data as demonstrated above.
Spark comes with a BitTorrent implementation.
It is not enabled by default.
Broadcast Contract
The Broadcast contract is made up of the following methods that custom Broadcast implementations are supposed to provide:
-
getValue -
doUnpersist -
doDestroy
|
Note
|
TorrentBroadcast is the only implementation of the Broadcast contract.
|
|
Note
|
Broadcast Spark Developer-Facing Contract is the developer-facing Broadcast contract that allows Spark developers to use it in their applications.
|