
ActiveJob
A job (aka action job or active job) is a top-level work item (computation) submitted to DAGScheduler to compute the result of an action (or for Adaptive Query Planning / Adaptive Scheduling).
Figure 1. RDD actions submit jobs to DAGScheduler
Computing a job is equivalent to computing the partitions of the RDD the action has been executed upon. The number of partitions in a job depends on the type of a stage - ResultStage or ShuffleMapStage.
A job starts with a single target RDD, but can ultimately include other RDDs that are all part of the target RDD’s lineage graph.
The parent stages are the instances of ShuffleMapStage.
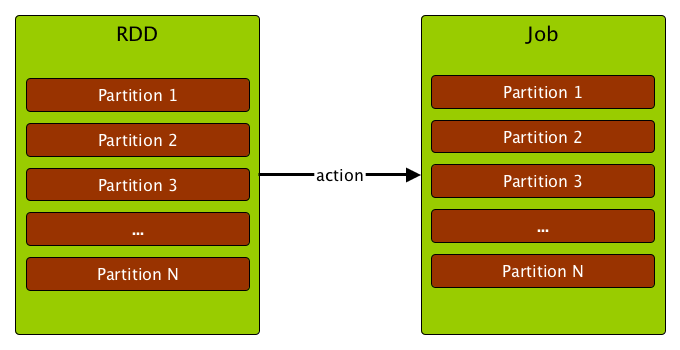
Figure 2. Computing a job is computing the partitions of an RDD
|
Note
|
Note that not all partitions have always to be computed for ResultStages for actions like first() and lookup().
|
Internally, a job is represented by an instance of private[spark] class org.apache.spark.scheduler.ActiveJob.
|
Caution
|
|
A job can be one of two logical types (that are only distinguished by an internal finalStage field of ActiveJob):
-
Map-stage job that computes the map output files for a ShuffleMapStage (for
submitMapStage) before any downstream stages are submitted.It is also used for Adaptive Query Planning / Adaptive Scheduling, to look at map output statistics before submitting later stages.
-
Result job that computes a ResultStage to execute an action.
Jobs track how many partitions have already been computed (using finished array of Boolean elements).