// million integers
val intsMM = 1 to math.pow(10, 6).toInt
// that gives ca 3.8 MB in memory
scala> sc.parallelize(intsMM).cache.count
res0: Long = 1000000
// that gives ca 998.4 KB in memory
scala> intsMM.toDF.cache.count
res1: Long = 1000000Tungsten Execution Backend (aka Project Tungsten)
The goal of Project Tungsten is to improve Spark execution by optimizing Spark jobs for CPU and memory efficiency (as opposed to network and disk I/O which are considered fast enough). Tungsten focuses on the hardware architecture of the platform Spark runs on, including but not limited to JVM, LLVM, GPU, NVRAM, etc. It does so by offering the following optimization features:
-
Off-Heap Memory Management using binary in-memory data representation aka Tungsten row format and managing memory explicitly,
-
Cache Locality which is about cache-aware computations with cache-aware layout for high cache hit rates,
-
Whole-Stage Code Generation (aka CodeGen).
|
Important
|
Project Tungsten uses sun.misc.unsafe API for direct memory access to bypass the JVM in order to avoid garbage collection.
|
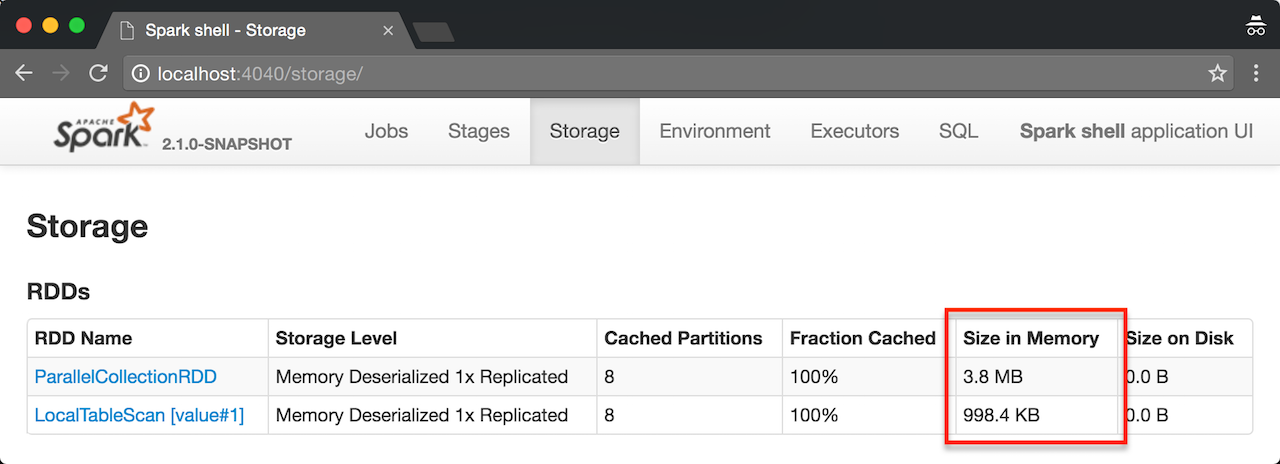
Figure 1. RDD vs DataFrame Size in Memory in web UI — Thank you, Tungsten!
Off-Heap Memory Management
Project Tungsten aims at substantially reducing the usage of JVM objects (and therefore JVM garbage collection) by introducing its own off-heap binary memory management. Instead of working with Java objects, Tungsten uses sun.misc.Unsafe to manipulate raw memory.
Tungsten uses the compact storage format called UnsafeRow for data representation that further reduces memory footprint.
Since Datasets have known schema, Tungsten properly and in a more compact and efficient way lays out the objects on its own. That brings benefits similar to using extensions written in low-level and hardware-aware languages like C or assembler.
It is possible immediately with the data being already serialized (that further reduces or completely avoids serialization between JVM object representation and Spark’s internal one).
Cache Locality
Tungsten uses algorithms and cache-aware data structures that exploit the physical machine caches at different levels - L1, L2, L3.
Whole-Stage Code Generation
Tungsten does code generation at compile time and generates JVM bytecode to access Tungsten-managed memory structures that gives a very fast access. It uses the Janino compiler — a super-small, super-fast Java compiler.
|
Note
|
The code generation was tracked under SPARK-8159 Improve expression function coverage (Spark 1.5). |
|
Tip
|
Read Whole-Stage Code Generation. |
Further reading or watching
-
(video) From DataFrames to Tungsten: A Peek into Spark’s Future by Reynold Xin (Databricks)
-
(video) Deep Dive into Project Tungsten: Bringing Spark Closer to Bare Metal by Josh Rosen (Databricks)