./sbin/start-master.sh
Example 2-workers-on-1-node Standalone Cluster (one executor per worker)
The following steps are a recipe for a Spark Standalone cluster with 2 workers on a single machine.
The aim is to have a complete Spark-clustered environment at your laptop.
|
Tip
|
Consult the following documents: |
|
Important
|
You can use the Spark Standalone cluster in the following ways:
For our learning purposes, |
-
Start a standalone master server.
Notes:
-
Use
SPARK_CONF_DIRfor the configuration directory (defaults to$SPARK_HOME/conf). -
Use
spark.deploy.retainedApplications(default:200) -
Use
spark.deploy.retainedDrivers(default:200) -
Use
spark.deploy.recoveryMode(default:NONE) -
Use
spark.deploy.defaultCores(default:Int.MaxValue)
-
Open master’s web UI at http://localhost:8080 to know the current setup - no workers and applications.
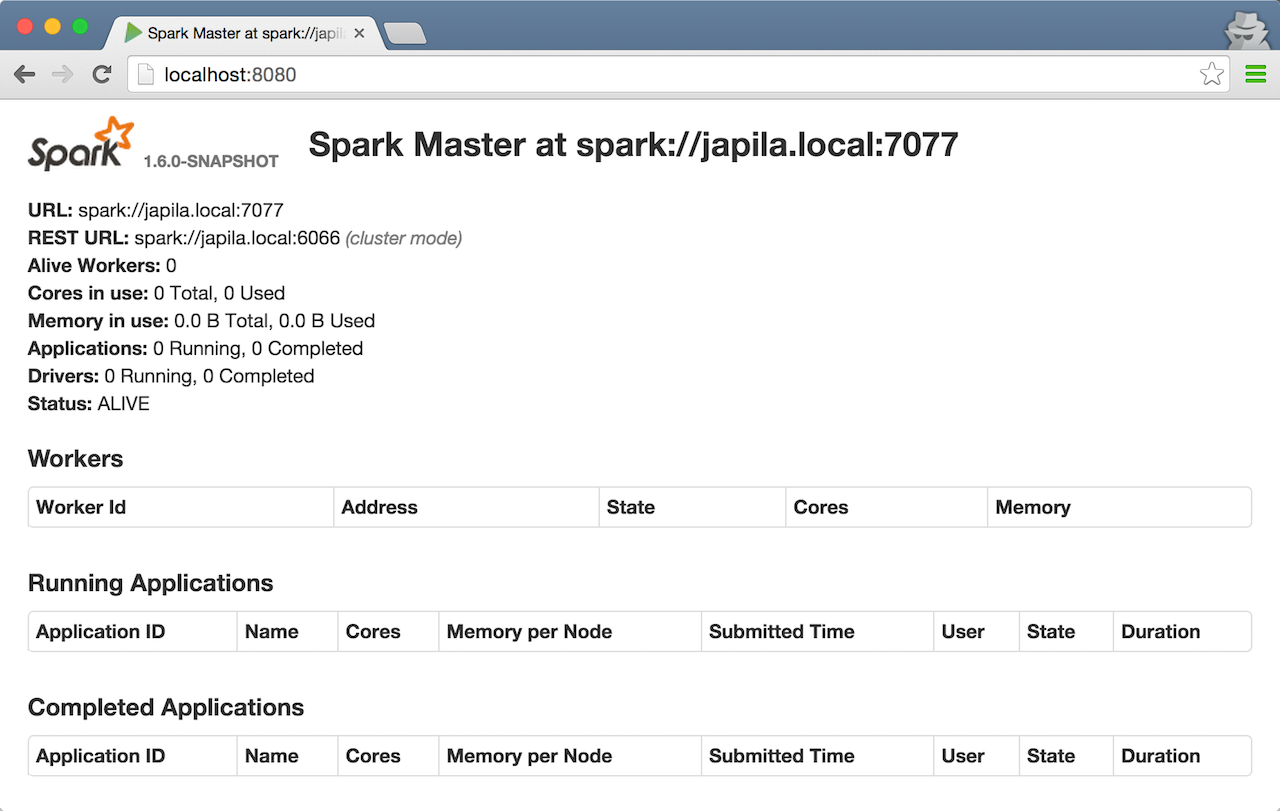 Figure 1. Master’s web UI with no workers and applications
Figure 1. Master’s web UI with no workers and applications -
Start the first worker.
./sbin/start-slave.sh spark://japila.local:7077
NoteThe command above in turn executes org.apache.spark.deploy.worker.Worker --webui-port 8081 spark://japila.local:7077 -
Check out master’s web UI at http://localhost:8080 to know the current setup - one worker.
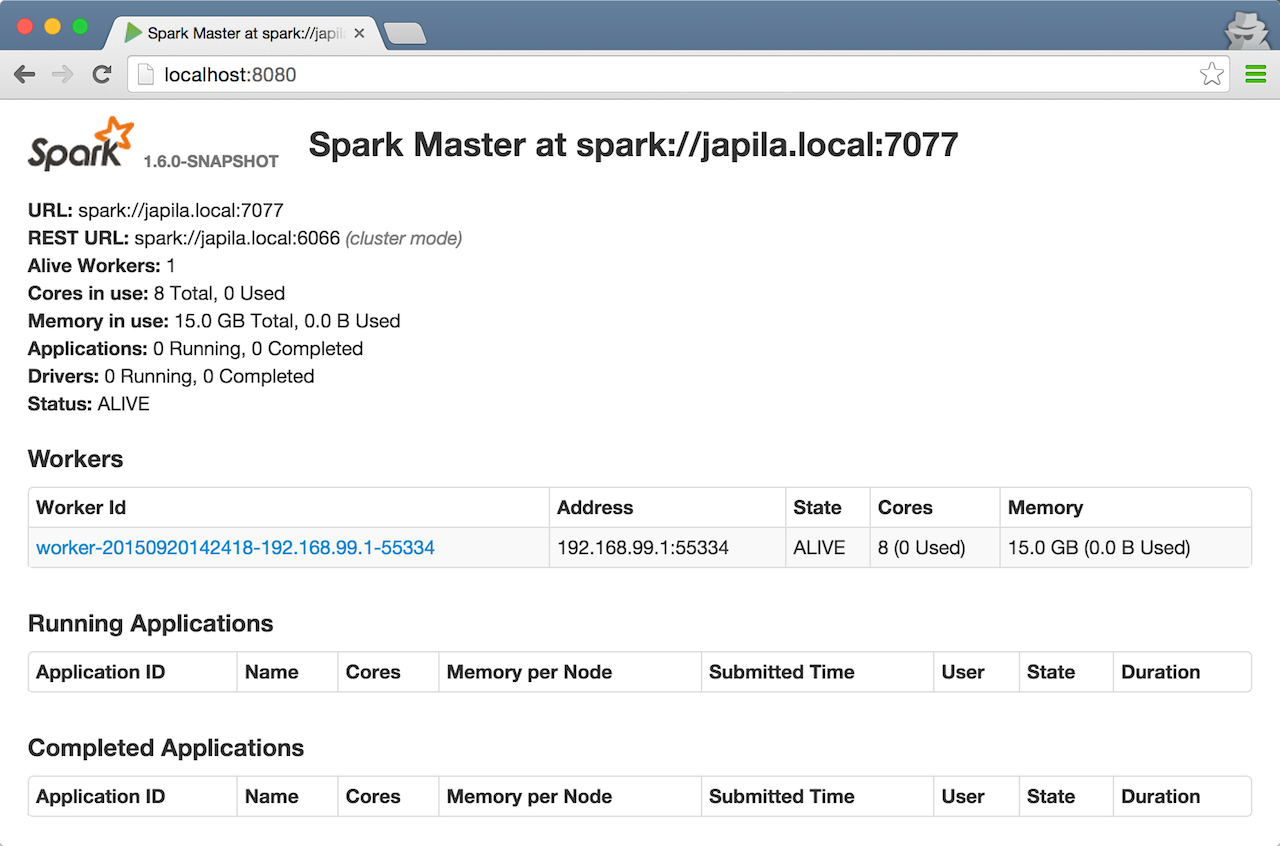 Figure 2. Master’s web UI with one worker ALIVE
Figure 2. Master’s web UI with one worker ALIVENote the number of CPUs and memory, 8 and 15 GBs, respectively (one gigabyte left for the OS — oh, how generous, my dear Spark!).
-
Let’s stop the worker to start over with custom configuration. You use
./sbin/stop-slave.shto stop the worker../sbin/stop-slave.sh
-
Check out master’s web UI at http://localhost:8080 to know the current setup - one worker in DEAD state.
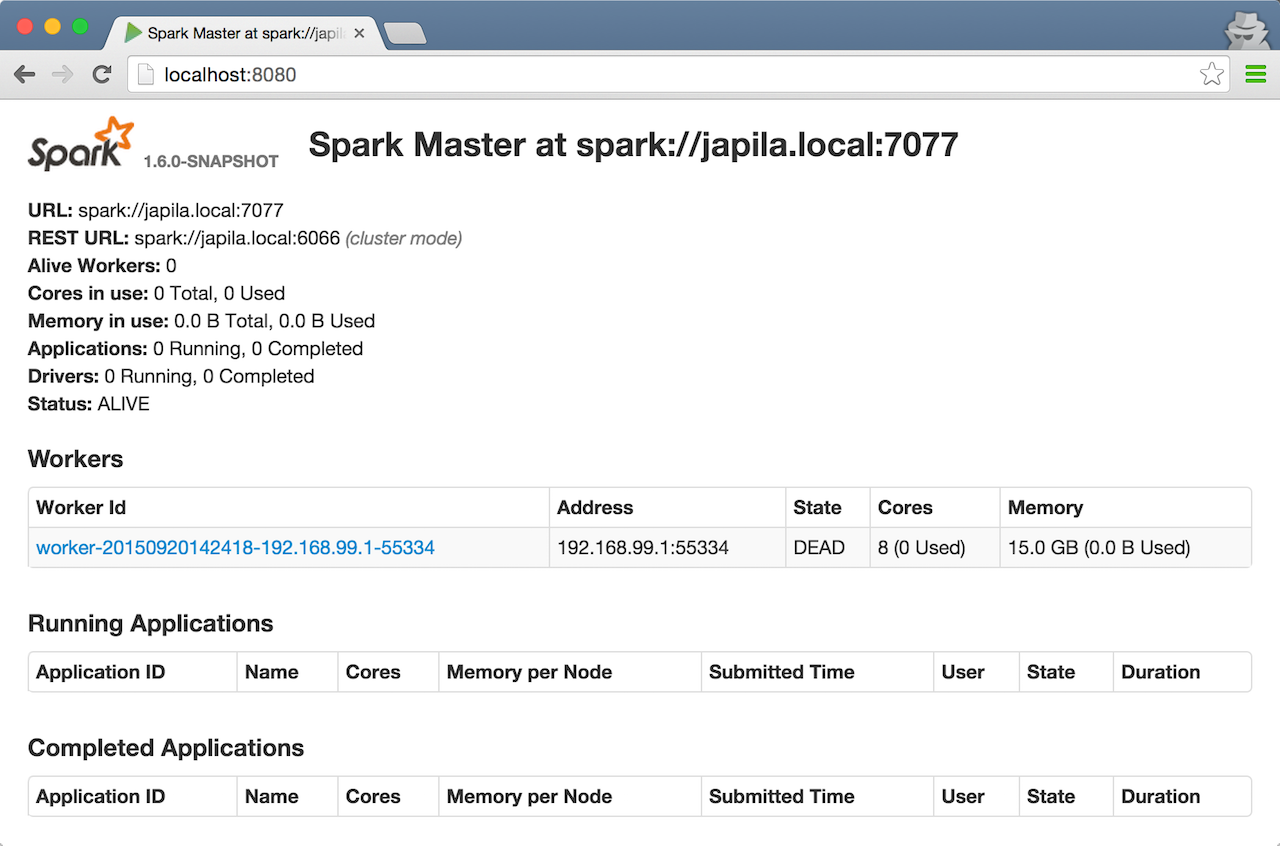 Figure 3. Master’s web UI with one worker DEAD
Figure 3. Master’s web UI with one worker DEAD -
Start a worker using
--cores 2and--memory 4gfor two CPU cores and 4 GB of RAM../sbin/start-slave.sh spark://japila.local:7077 --cores 2 --memory 4g
NoteThe command translates to org.apache.spark.deploy.worker.Worker --webui-port 8081 spark://japila.local:7077 --cores 2 --memory 4g -
Check out master’s web UI at http://localhost:8080 to know the current setup - one worker ALIVE and another DEAD.
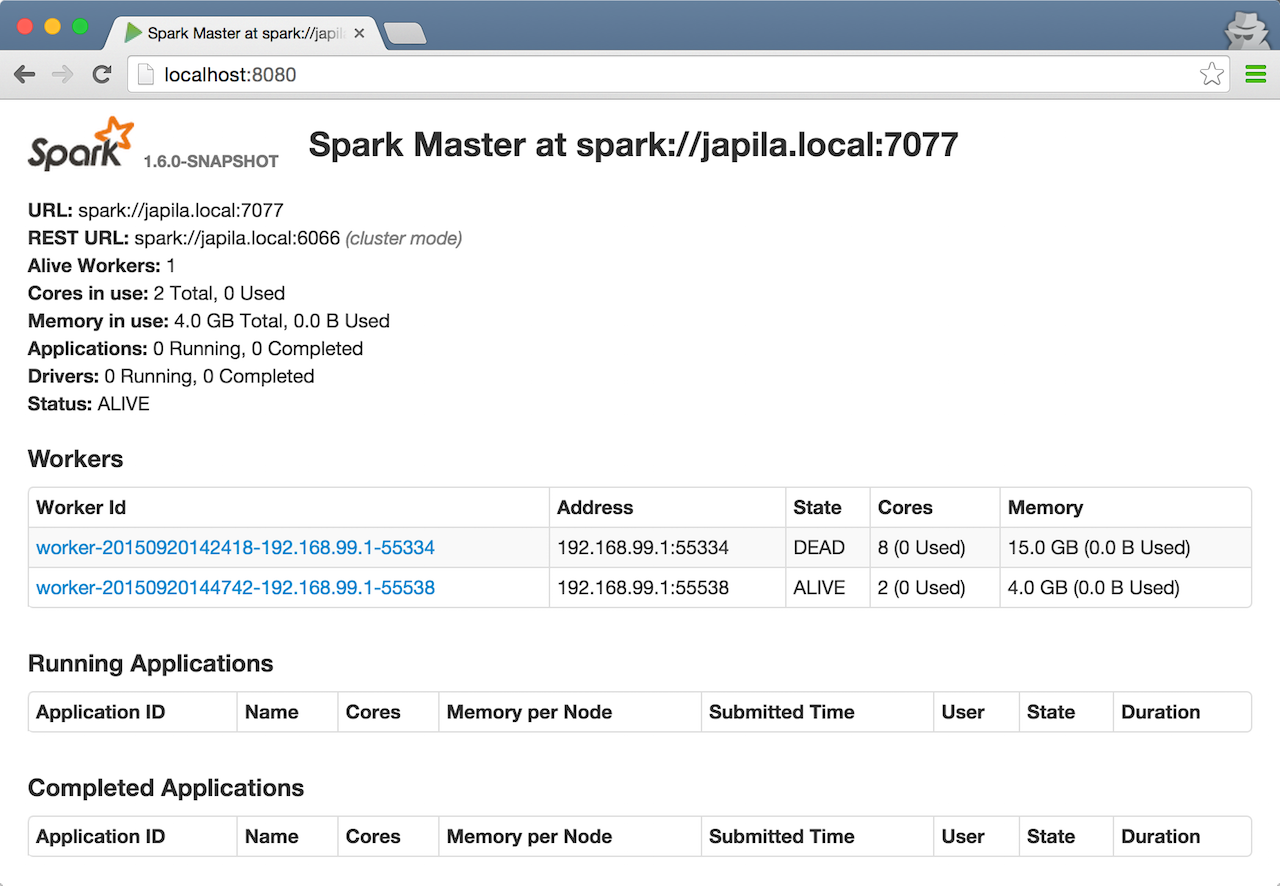 Figure 4. Master’s web UI with one worker ALIVE and one DEAD
Figure 4. Master’s web UI with one worker ALIVE and one DEAD -
Configuring cluster using
conf/spark-env.shThere’s the
conf/spark-env.sh.templatetemplate to start from.We’re going to use the following
conf/spark-env.sh:conf/spark-env.shSPARK_WORKER_CORES=2 (1) SPARK_WORKER_INSTANCES=2 (2) SPARK_WORKER_MEMORY=2g-
the number of cores per worker
-
the number of workers per node (a machine)
-
-
Start the workers.
./sbin/start-slave.sh spark://japila.local:7077
As the command progresses, it prints out starting org.apache.spark.deploy.worker.Worker, logging to for each worker. You defined two workers in
conf/spark-env.shusingSPARK_WORKER_INSTANCES, so you should see two lines.$ ./sbin/start-slave.sh spark://japila.local:7077 starting org.apache.spark.deploy.worker.Worker, logging to ../logs/spark-jacek-org.apache.spark.deploy.worker.Worker-1-japila.local.out starting org.apache.spark.deploy.worker.Worker, logging to ../logs/spark-jacek-org.apache.spark.deploy.worker.Worker-2-japila.local.out
-
Check out master’s web UI at http://localhost:8080 to know the current setup - at least two workers should be ALIVE.
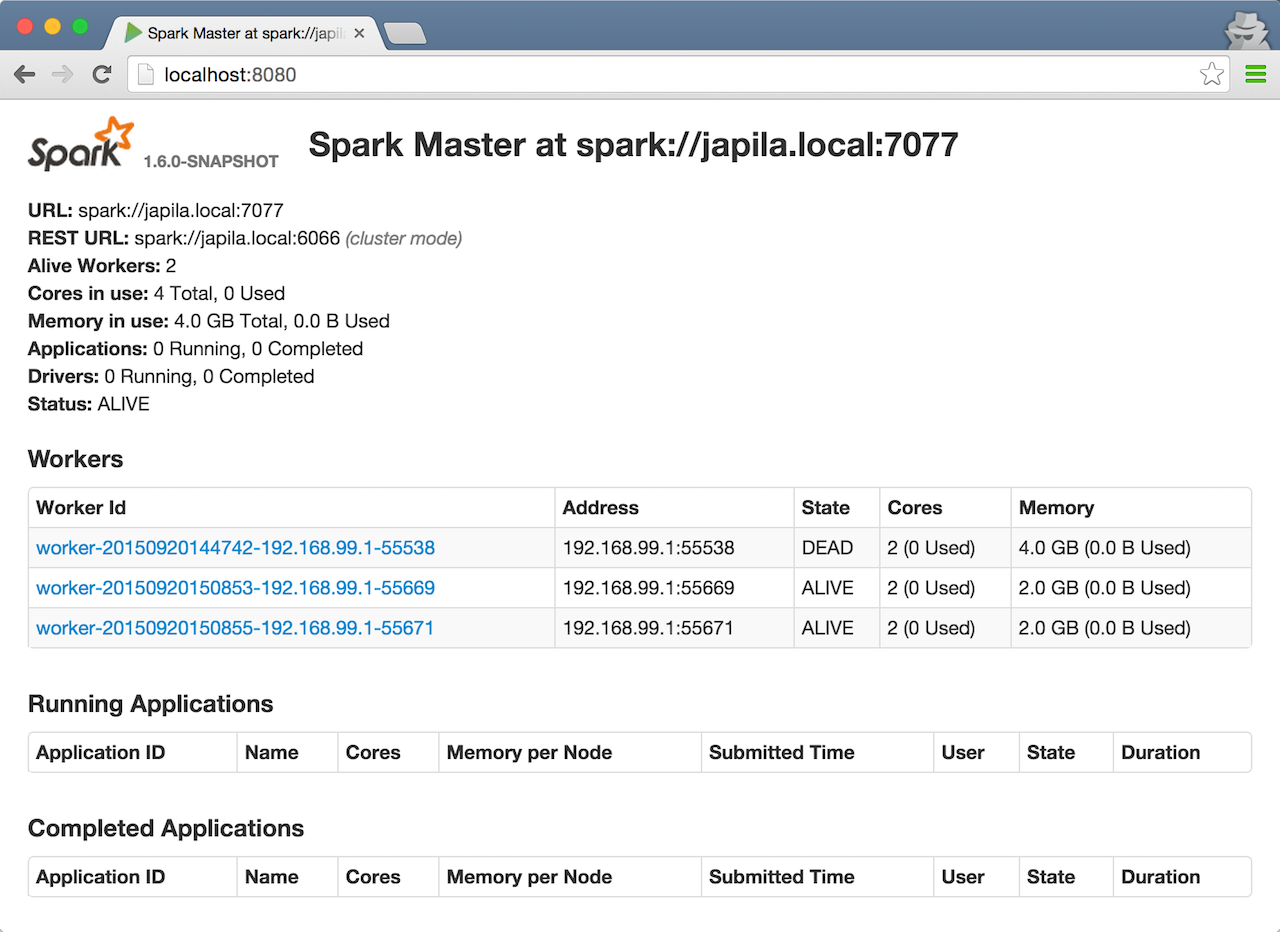 Figure 5. Master’s web UI with two workers ALIVENote
Figure 5. Master’s web UI with two workers ALIVENoteUse
jpson master to see the instances given they all run on the same machine, e.g.localhost).$ jps 6580 Worker 4872 Master 6874 Jps 6539 Worker
-
Stop all instances - the driver and the workers.
./sbin/stop-all.sh