Executor
Executor is a distributed agent that is responsible for executing tasks.
Executor is created when:
-
CoarseGrainedExecutorBackendreceivesRegisteredExecutormessage (for Spark Standalone and YARN) -
Spark on Mesos’s
MesosExecutorBackenddoesregistered -
LocalEndpointis created (for local mode)
Executor typically runs for the entire lifetime of a Spark application which is called static allocation of executors (but you could also opt in for dynamic allocation).
|
Note
|
Executors are managed exclusively by executor backends. |
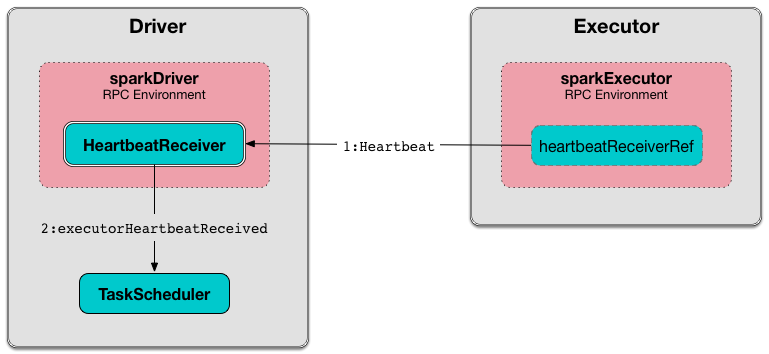
Executors reports heartbeat and partial metrics for active tasks to HeartbeatReceiver RPC Endpoint on the driver.
Figure 1. HeartbeatReceiver’s Heartbeat Message Handler
Executors provide in-memory storage for RDDs that are cached in Spark applications (via Block Manager).
When an executor starts it first registers with the driver and communicates directly to execute tasks.
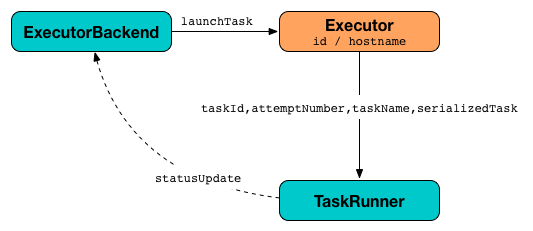
Figure 2. Launching tasks on executor using TaskRunners
Executor offers are described by executor id and the host on which an executor runs (see Resource Offers in this document).
Executors can run multiple tasks over its lifetime, both in parallel and sequentially. They track running tasks (by their task ids in runningTasks internal registry). Consult Launching Tasks section.
Executors use a Executor task launch worker thread pool for launching tasks.
Executors send metrics (and heartbeats) using the internal heartbeater - Heartbeat Sender Thread.
It is recommended to have as many executors as data nodes and as many cores as you can get from the cluster.
Executors are described by their id, hostname, environment (as SparkEnv), and classpath (and, less importantly, and more for internal optimization, whether they run in local or cluster mode).
|
Caution
|
FIXME How many cores are assigned per executor? |
| Name | Initial Value | Description |
|---|---|---|
| Name | Description |
|---|---|
RPC endpoint reference to HeartbeatReceiver on the driver (available on spark.driver.host at spark.driver.port port). Set when Used exclusively when |
|
Lookup table of TaskRunners per…FIXME |
|
Tip
|
Enable Add the following line to Refer to Logging. |
createClassLoader Method
|
Caution
|
FIXME |
addReplClassLoaderIfNeeded Method
|
Caution
|
FIXME |
Creating Executor Instance
Executor takes the following when created:
-
Collection of user-defined JARs (to add to tasks' class path). Empty by default
-
Flag whether it runs in local or cluster mode (disabled by default, i.e. cluster is preferred)
|
Note
|
User-defined JARs are defined using --user-class-path command-line option of CoarseGrainedExecutorBackend that can be set using spark.executor.extraClassPath property.
|
|
Note
|
isLocal is enabled exclusively for LocalEndpoint (for Spark in local mode).
|
When created, you should see the following INFO messages in the logs:
INFO Executor: Starting executor ID [executorId] on host [executorHostname](only for non-local mode) Executor sets SparkUncaughtExceptionHandler as the default handler invoked when a thread abruptly terminates due to an uncaught exception.
(only for non-local mode) Executor registers ExecutorSource and initializes the local BlockManager.
|
Note
|
Executor uses SparkEnv to access the local MetricsSystem and BlockManager.
|
Executor creates a task class loader (optionally with REPL support) that the current Serializer is requested to use (when deserializing task later).
|
Note
|
Executor uses SparkEnv to access the local Serializer.
|
Executor initializes the internal registries and counters in the meantime (not necessarily at the very end).
Launching Task — launchTask Method
launchTask(
context: ExecutorBackend,
taskId: Long,
attemptNumber: Int,
taskName: String,
serializedTask: ByteBuffer): UnitlaunchTask executes the input serializedTask task concurrently.
Internally, launchTask creates a TaskRunner, registers it in runningTasks internal registry (by taskId), and finally executes it on "Executor task launch worker" thread pool.
Figure 3. Launching tasks on executor using TaskRunners
|
Note
|
launchTask is called by CoarseGrainedExecutorBackend (when it handles LaunchTask message), MesosExecutorBackend, and LocalEndpoint.
|
Sending Heartbeats and Active Tasks Metrics — startDriverHeartbeater Method
Executors keep sending metrics for active tasks to the driver every spark.executor.heartbeatInterval (defaults to 10s with some random initial delay so the heartbeats from different executors do not pile up on the driver).
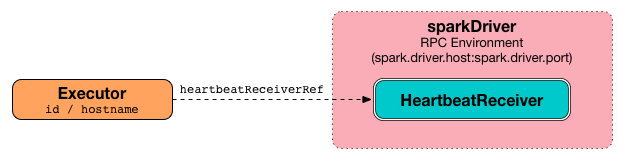
Figure 4. Executors use HeartbeatReceiver endpoint to report task metrics
An executor sends heartbeats using the internal heartbeater — Heartbeat Sender Thread.
Figure 5. HeartbeatReceiver’s Heartbeat Message Handler
For each task in TaskRunner (in runningTasks internal registry), the task’s metrics are computed (i.e. mergeShuffleReadMetrics and setJvmGCTime) that become part of the heartbeat (with accumulators).
|
Caution
|
FIXME How do mergeShuffleReadMetrics and setJvmGCTime influence accumulators?
|
|
Note
|
Executors track the TaskRunner that run tasks. A task might not be assigned to a TaskRunner yet when the executor sends a heartbeat. |
A blocking Heartbeat message that holds the executor id, all accumulator updates (per task id), and BlockManagerId is sent to HeartbeatReceiver RPC endpoint (with spark.executor.heartbeatInterval timeout).
|
Caution
|
FIXME When is heartbeatReceiverRef created?
|
If the response requests to reregister BlockManager, you should see the following INFO message in the logs:
INFO Executor: Told to re-register on heartbeatThe internal heartbeatFailures counter is reset (i.e. becomes 0).
If there are any issues with communicating with the driver, you should see the following WARN message in the logs:
WARN Executor: Issue communicating with driver in heartbeaterThe internal heartbeatFailures is incremented and checked to be less than the acceptable number of failures (i.e. spark.executor.heartbeat.maxFailures Spark property). If the number is greater, the following ERROR is printed out to the logs:
ERROR Executor: Exit as unable to send heartbeats to driver more than [HEARTBEAT_MAX_FAILURES] timesThe executor exits (using System.exit and exit code 56).
|
Tip
|
Read about TaskMetrics in TaskMetrics.
|
Reporting Heartbeat and Partial Metrics for Active Tasks to Driver — reportHeartBeat Internal Method
reportHeartBeat(): UnitreportHeartBeat collects TaskRunners for currently running tasks (aka active tasks) with their tasks deserialized (i.e. either ready for execution or already started).
|
Note
|
TaskRunner has task deserialized when it runs the task. |
For every running task, reportHeartBeat takes its TaskMetrics and:
reportHeartBeat then records the latest values of internal and external accumulators for every task.
|
Note
|
Internal accumulators are a task’s metrics while external accumulators are a Spark application’s accumulators that a user has created. |
reportHeartBeat sends a blocking Heartbeat message to HeartbeatReceiver endpoint (running on the driver). reportHeartBeat uses spark.executor.heartbeatInterval for the RPC timeout.
|
Note
|
A Heartbeat message contains the executor identifier, the accumulator updates, and the identifier of the BlockManager.
|
|
Note
|
reportHeartBeat uses SparkEnv to access the current BlockManager.
|
If the response (from HeartbeatReceiver endpoint) is to re-register the BlockManager, you should see the following INFO message in the logs and reportHeartBeat requests BlockManager to re-register (which will register the blocks the BlockManager manages with the driver).
INFO Told to re-register on heartbeat|
Note
|
HeartbeatResponse requests BlockManager to re-register when either TaskScheduler or HeartbeatReceiver know nothing about the executor.
|
When posting the Heartbeat was successful, reportHeartBeat resets heartbeatFailures internal counter.
In case of a non-fatal exception, you should see the following WARN message in the logs (followed by the stack trace).
WARN Issue communicating with driver in heartbeaterEvery failure reportHeartBeat increments heartbeat failures up to spark.executor.heartbeat.maxFailures Spark property. When the heartbeat failures reaches the maximum, you should see the following ERROR message in the logs and the executor terminates with the error code: 56.
ERROR Exit as unable to send heartbeats to driver more than [HEARTBEAT_MAX_FAILURES] times|
Note
|
reportHeartBeat is used when Executor schedules reporting heartbeat and partial metrics for active tasks to the driver (that happens every spark.executor.heartbeatInterval Spark property).
|
heartbeater — Heartbeat Sender Thread
heartbeater is a daemon ScheduledThreadPoolExecutor with a single thread.
The name of the thread pool is driver-heartbeater.
Coarse-Grained Executors
Coarse-grained executors are executors that use CoarseGrainedExecutorBackend for task scheduling.
Resource Offers
Read resourceOffers in TaskSchedulerImpl and resourceOffer in TaskSetManager.
"Executor task launch worker" Thread Pool — threadPool Property
Executor uses threadPool daemon cached thread pool with the name Executor task launch worker-[ID] (with ID being the task id) for launching tasks.
threadPool is created when Executor is created and shut down when it stops.
Executor Memory — spark.executor.memory or SPARK_EXECUTOR_MEMORY settings
You can control the amount of memory per executor using spark.executor.memory setting. It sets the available memory equally for all executors per application.
|
Note
|
The amount of memory per executor is looked up when SparkContext is created. |
You can change the assigned memory per executor per node in standalone cluster using SPARK_EXECUTOR_MEMORY environment variable.
You can find the value displayed as Memory per Node in web UI for standalone Master (as depicted in the figure below).
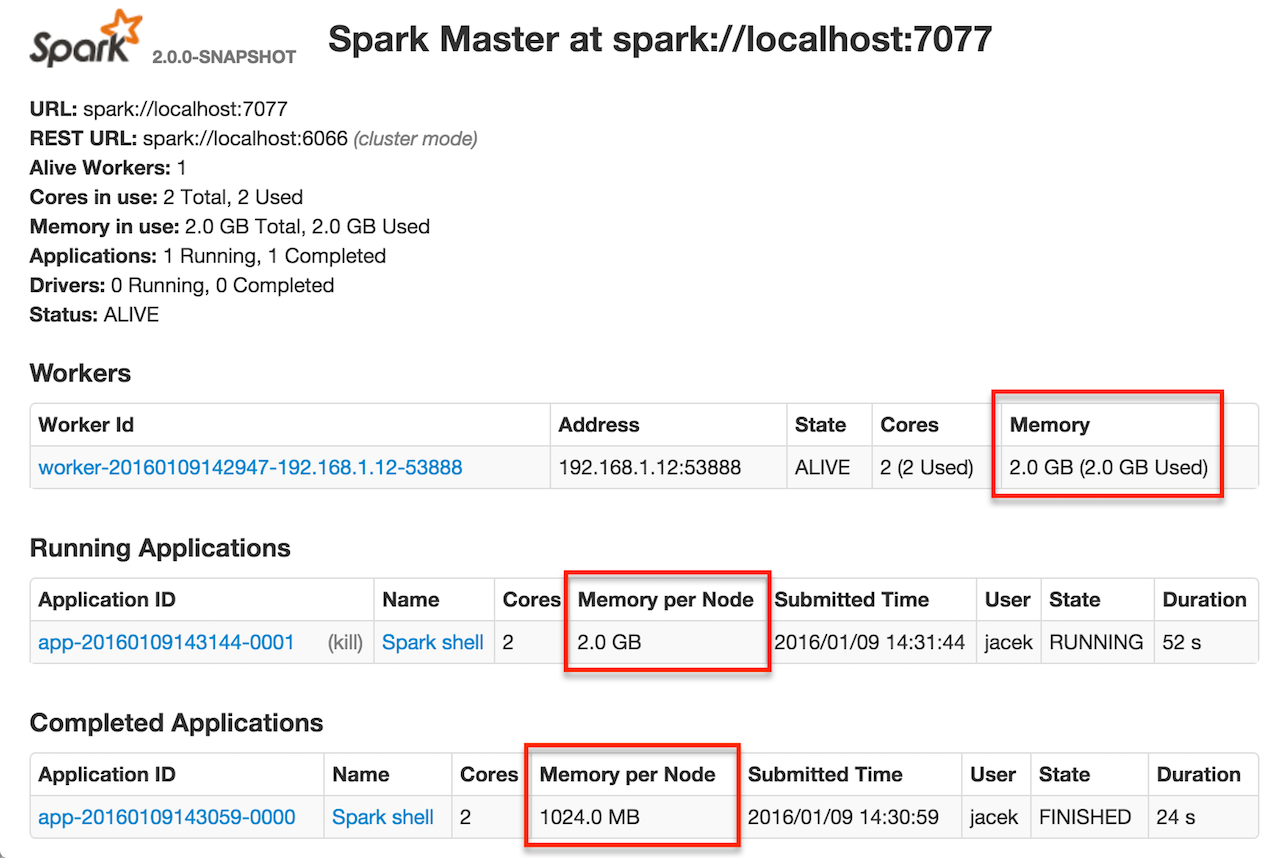
Figure 6. Memory per Node in Spark Standalone’s web UI
The above figure shows the result of running Spark shell with the amount of memory per executor defined explicitly (on command line), i.e.
./bin/spark-shell --master spark://localhost:7077 -c spark.executor.memory=2gMetrics
Every executor registers its own ExecutorSource to report metrics.
Stopping Executor — stop Method
stop(): Unit|
Note
|
stop uses SparkEnv to access the current MetricsSystem.
|
stop shuts driver-heartbeater thread down (and waits at most 10 seconds).
stop shuts Executor task launch worker thread pool down.
(only when not local) stop requests SparkEnv to stop.
|
Note
|
stop is used when CoarseGrainedExecutorBackend and LocalEndpoint are requested to stop their managed executors.
|
Settings
| Spark Property | Default Value | Description |
|---|---|---|
Number of cores for an executor. |
||
(empty) |
List of URLs representing user-defined class path entries that are added to an executor’s class path. Each entry is separated by system-dependent path separator, i.e. |
|
Extra Java options for executors. Used to prepare the command to launch |
||
Extra library paths separated by system-dependent path separator, i.e. Used to prepare the command to launch |
||
|
Number of times an executor will try to send heartbeats to the driver before it gives up and exits (with exit code NOTE: It was introduced in SPARK-13522 Executor should kill itself when it’s unable to heartbeat to the driver more than N times. |
|
|
Interval after which an executor reports heartbeat and metrics for active tasks to the driver. Refer to Sending heartbeats and partial metrics for active tasks in this document. |
|
|
Number of executors to use. |
|
|
||
|
||
|
||
|
||
|
Amount of memory to use per executor process. Equivalent to SPARK_EXECUTOR_MEMORY environment variable. Refer to Executor Memory — spark.executor.memory or SPARK_EXECUTOR_MEMORY settings in this document. |
|
|
||
|
Flag to control whether to load classes in user jars before those in Spark jars. |
|
|
Equivalent to |
|
|