The origins of RDD
The original paper that gave birth to the concept of RDD is Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing by Matei Zaharia, et al.
Resilient Distributed Dataset (aka RDD) is the primary data abstraction in Apache Spark and the core of Spark (that I often refer to as "Spark Core").
A RDD is a resilient and distributed collection of records spread over one or many partitions.
|
Note
|
One could compare RDDs to collections in Scala, i.e. a RDD is computed on many JVMs while a Scala collection lives on a single JVM. |
Using RDD Spark hides data partitioning and so distribution that in turn allowed them to design parallel computational framework with a higher-level programming interface (API) for four mainstream programming languages.
The features of RDDs (decomposing the name):
Resilient, i.e. fault-tolerant with the help of RDD lineage graph and so able to recompute missing or damaged partitions due to node failures.
Distributed with data residing on multiple nodes in a cluster.
Dataset is a collection of partitioned data with primitive values or values of values, e.g. tuples or other objects (that represent records of the data you work with).
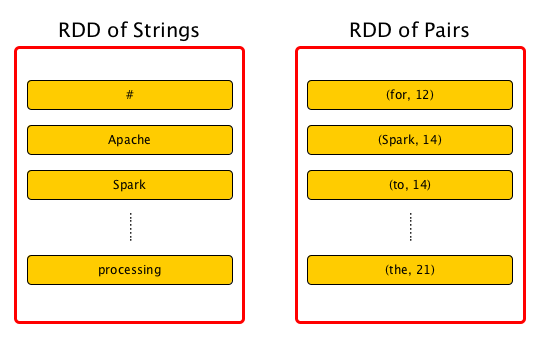
From the scaladoc of org.apache.spark.rdd.RDD:
A Resilient Distributed Dataset (RDD), the basic abstraction in Spark. Represents an immutable, partitioned collection of elements that can be operated on in parallel.
From the original paper about RDD - Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing:
Resilient Distributed Datasets (RDDs) are a distributed memory abstraction that lets programmers perform in-memory computations on large clusters in a fault-tolerant manner.
Beside the above traits (that are directly embedded in the name of the data abstraction - RDD) it has the following additional traits:
In-Memory, i.e. data inside RDD is stored in memory as much (size) and long (time) as possible.
Immutable or Read-Only, i.e. it does not change once created and can only be transformed using transformations to new RDDs.
Lazy evaluated, i.e. the data inside RDD is not available or transformed until an action is executed that triggers the execution.
Cacheable, i.e. you can hold all the data in a persistent "storage" like memory (default and the most preferred) or disk (the least preferred due to access speed).
Parallel, i.e. process data in parallel.
Typed — RDD records have types, e.g. Long in RDD[Long] or (Int, String) in RDD[(Int, String)].
Partitioned — records are partitioned (split into logical partitions) and distributed across nodes in a cluster.
Location-Stickiness — RDD can define placement preferences to compute partitions (as close to the records as possible).
|
Note
|
Preferred location (aka locality preferences or placement preferences or locality info) is information about the locations of RDD records (that Spark’s DAGScheduler uses to place computing partitions on to have the tasks as close to the data as possible). |
Computing partitions in a RDD is a distributed process by design and to achieve even data distribution as well as leverage data locality (in distributed systems like HDFS or Cassandra in which data is partitioned by default), they are partitioned to a fixed number of partitions - logical chunks (parts) of data. The logical division is for processing only and internally it is not divided whatsoever. Each partition comprises of records.
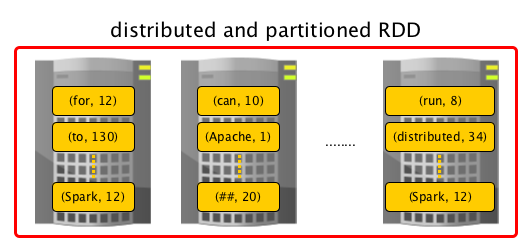
Partitions are the units of parallelism. You can control the number of partitions of a RDD using repartition or coalesce transformations. Spark tries to be as close to data as possible without wasting time to send data across network by means of RDD shuffling, and creates as many partitions as required to follow the storage layout and thus optimize data access. It leads to a one-to-one mapping between (physical) data in distributed data storage, e.g. HDFS or Cassandra, and partitions.
RDDs support two kinds of operations:
transformations - lazy operations that return another RDD.
actions - operations that trigger computation and return values.
The motivation to create RDD were (after the authors) two types of applications that current computing frameworks handle inefficiently:
iterative algorithms in machine learning and graph computations.
interactive data mining tools as ad-hoc queries on the same dataset.
The goal is to reuse intermediate in-memory results across multiple data-intensive workloads with no need for copying large amounts of data over the network.
Technically, RDDs follow the contract defined by the five main intrinsic properties:
List of parent RDDs that are the dependencies of the RDD.
An array of partitions that a dataset is divided to.
A compute function to do a computation on partitions.
An optional Partitioner that defines how keys are hashed, and the pairs partitioned (for key-value RDDs)
Optional preferred locations (aka locality info), i.e. hosts for a partition where the records live or are the closest to read from.
This RDD abstraction supports an expressive set of operations without having to modify scheduler for each one.
An RDD is a named (by name) and uniquely identified (by id) entity in a SparkContext (available as context property).
RDDs live in one and only one SparkContext that creates a logical boundary.
|
Note
|
RDDs cannot be shared between SparkContexts (see SparkContext and RDDs).
|
An RDD can optionally have a friendly name accessible using name that can be changed using =:
scala> val ns = sc.parallelize(0 to 10)
ns: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[2] at parallelize at <console>:24
scala> ns.id
res0: Int = 2
scala> ns.name
res1: String = null
scala> ns.name = "Friendly name"
ns.name: String = Friendly name
scala> ns.name
res2: String = Friendly name
scala> ns.toDebugString
res3: String = (8) Friendly name ParallelCollectionRDD[2] at parallelize at <console>:24 []RDDs are a container of instructions on how to materialize big (arrays of) distributed data, and how to split it into partitions so Spark (using executors) can hold some of them.
In general data distribution can help executing processing in parallel so a task processes a chunk of data that it could eventually keep in memory.
Spark does jobs in parallel, and RDDs are split into partitions to be processed and written in parallel. Inside a partition, data is processed sequentially.
Saving partitions results in part-files instead of one single file (unless there is a single partition).
checkpointRDD Internal Method|
Caution
|
FIXME |
isCheckpointedAndMaterialized Method|
Caution
|
FIXME |
getNarrowAncestors Method|
Caution
|
FIXME |
toLocalIterator Method|
Caution
|
FIXME |
cache Method|
Caution
|
FIXME |
persist Methodspersist(): this.type
persist(newLevel: StorageLevel): this.typeRefer to Persisting RDD — persist Methods.
persist Internal Methodpersist(newLevel: StorageLevel, allowOverride: Boolean): this.type|
Caution
|
FIXME |
|
Note
|
persist is used when RDD is requested to persist itself and marks itself for local checkpointing.
|
unpersist Method|
Caution
|
FIXME |
abstract class RDD[T] {
def compute(split: Partition, context: TaskContext): Iterator[T]
def getPartitions: Array[Partition]
def getDependencies: Seq[Dependency[_]]
def getPreferredLocations(split: Partition): Seq[String] = Nil
val partitioner: Option[Partitioner] = None
}|
Note
|
RDD is an abstract class in Scala.
|
| Method | Description |
|---|---|
Used exclusively when |
|
Used exclusively when |
|
Used when |
|
Defines placement preferences of a partition. Used exclusively when |
|
Defines the Partitioner of a |
There are some of the most interesting types of RDDs:
HadoopRDD is an RDD that provides core functionality for reading data stored in HDFS using the older MapReduce API. The most notable use case is the return RDD of SparkContext.textFile.
MapPartitionsRDD - a result of calling operations like map, flatMap, filter, mapPartitions, etc.
CoalescedRDD - a result of repartition or coalesce transformations.
ShuffledRDD - a result of shuffling, e.g. after repartition or coalesce transformations.
PipedRDD - an RDD created by piping elements to a forked external process.
PairRDD (implicit conversion by PairRDDFunctions) that is an RDD of key-value pairs that is a result of groupByKey and join operations.
DoubleRDD (implicit conversion as org.apache.spark.rdd.DoubleRDDFunctions) that is an RDD of Double type.
SequenceFileRDD (implicit conversion as org.apache.spark.rdd.SequenceFileRDDFunctions) that is an RDD that can be saved as a SequenceFile.
Appropriate operations of a given RDD type are automatically available on a RDD of the right type, e.g. RDD[(Int, Int)], through implicit conversion in Scala.
A transformation is a lazy operation on a RDD that returns another RDD, like map, flatMap, filter, reduceByKey, join, cogroup, etc.
|
Tip
|
Go in-depth in the section Transformations. |
An action is an operation that triggers execution of RDD transformations and returns a value (to a Spark driver - the user program).
|
Tip
|
Go in-depth in the section Actions. |
One way to create a RDD is with SparkContext.parallelize method. It accepts a collection of elements as shown below (sc is a SparkContext instance):
scala> val rdd = sc.parallelize(1 to 1000)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:25You may also want to randomize the sample data:
scala> val data = Seq.fill(10)(util.Random.nextInt)
data: Seq[Int] = List(-964985204, 1662791, -1820544313, -383666422, -111039198, 310967683, 1114081267, 1244509086, 1797452433, 124035586)
scala> val rdd = sc.parallelize(data)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:29Given the reason to use Spark to process more data than your own laptop could handle, SparkContext.parallelize is mainly used to learn Spark in the Spark shell. SparkContext.parallelize requires all the data to be available on a single machine - the Spark driver - that eventually hits the limits of your laptop.
|
Caution
|
FIXME What’s the use case for makeRDD?
|
scala> sc.makeRDD(0 to 1000)
res0: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at makeRDD at <console>:25One of the easiest ways to create an RDD is to use SparkContext.textFile to read files.
You can use the local README.md file (and then flatMap over the lines inside to have an RDD of words):
scala> val words = sc.textFile("README.md").flatMap(_.split("\\W+")).cache
words: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[27] at flatMap at <console>:24|
Note
|
You cache it so the computation is not performed every time you work with words.
|
Refer to Using Input and Output (I/O) to learn about the IO API to create RDDs.
RDD transformations by definition transform an RDD into another RDD and hence are the way to create new ones.
Refer to Transformations section to learn more.
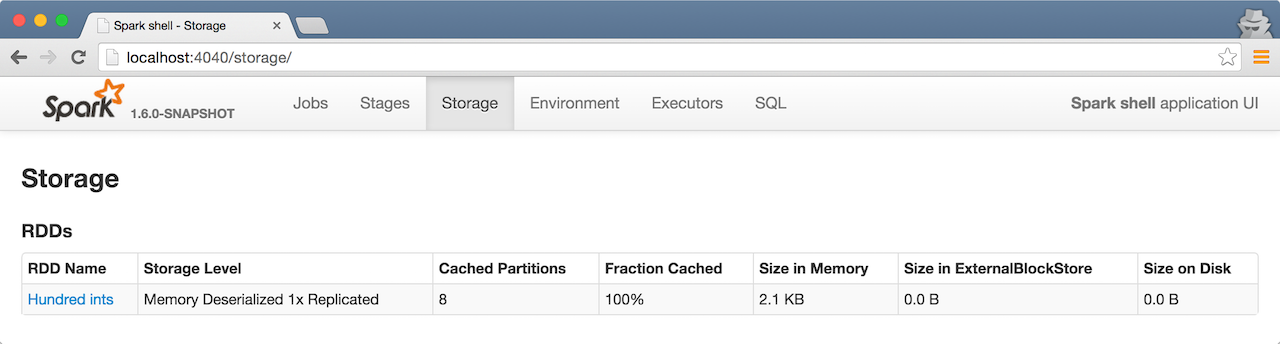
It is quite informative to look at RDDs in the Web UI that is at http://localhost:4040 for Spark shell.
Execute the following Spark application (type all the lines in spark-shell):
val ints = sc.parallelize(1 to 100) (1)
ints.setName("Hundred ints") (2)
ints.cache (3)
ints.count (4)Creates an RDD with hundred of numbers (with as many partitions as possible)
Sets the name of the RDD
Caches the RDD for performance reasons that also makes it visible in Storage tab in the web UI
Executes action (and materializes the RDD)
With the above executed, you should see the following in the Web UI:
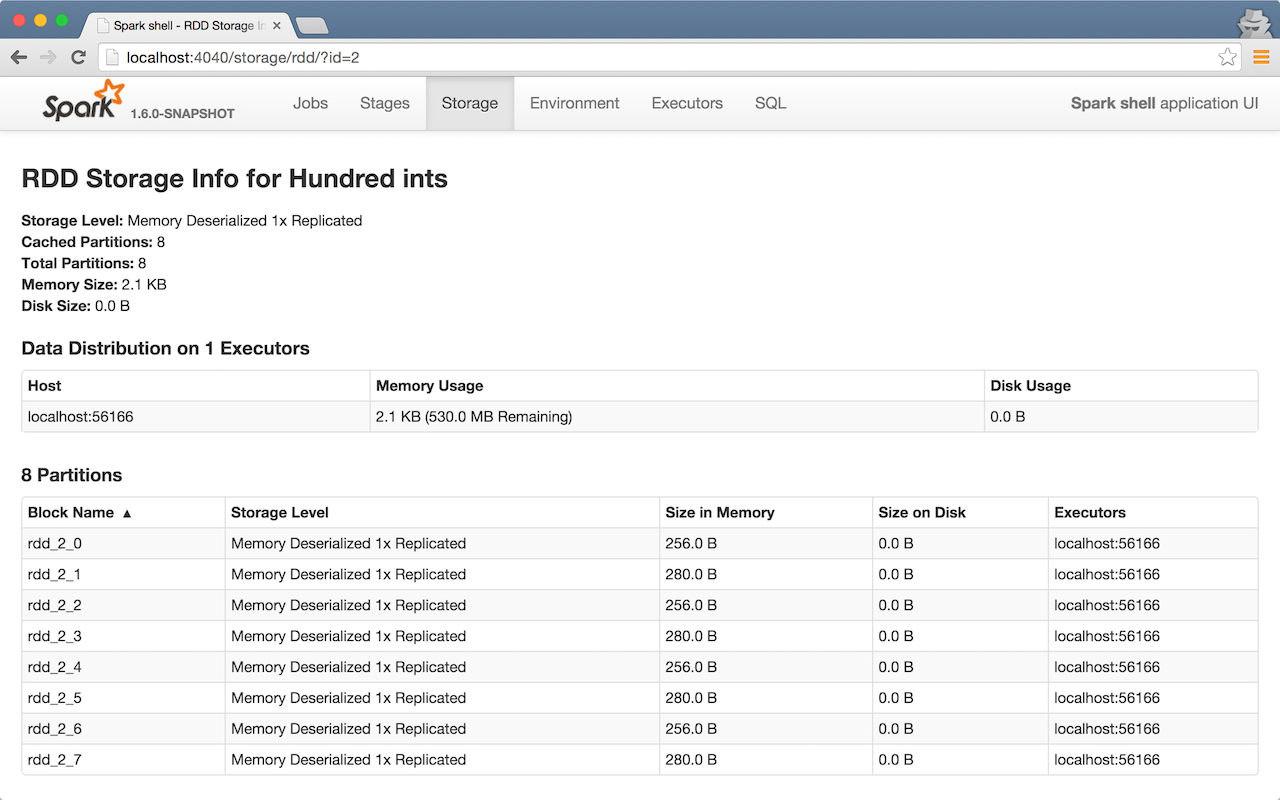
Click the name of the RDD (under RDD Name) and you will get the details of how the RDD is cached.
Execute the following Spark job and you will see how the number of partitions decreases.
ints.repartition(2).count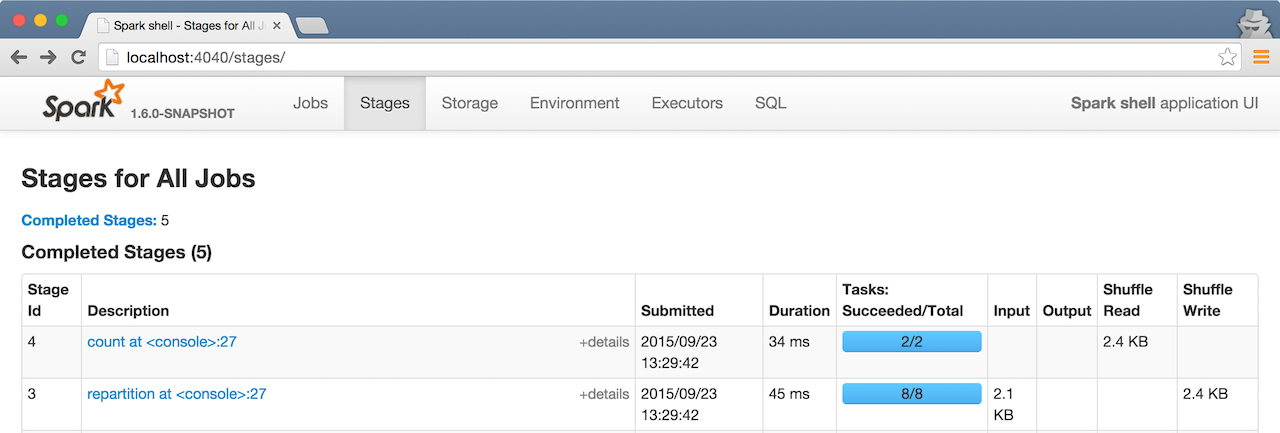
repartitionpartitions Final Methodpartitions: Array[Partition]partitions returns the Partitions of a RDD.
partitions requests CheckpointRDD for partitions (if the RDD is checkpointed) or finds them itself and cache (in partitions_ internal registry that is used next time).
|
Note
|
Partitions have the property that their internal index should be equal to their position in the owning RDD. |
compute Methodcompute(split: Partition, context: TaskContext): Iterator[T]The abstract compute method computes the input split partition in the TaskContext to produce a collection of values (of type T).
compute is implemented by any type of RDD in Spark and is called every time the records are requested unless RDD is cached or checkpointed (and the records can be read from an external storage, but this time closer to the compute node).
When an RDD is cached, for specified storage levels (i.e. all but NONE) CacheManager is requested to get or compute partitions.
|
Note
|
compute method runs on the driver.
|
preferredLocations Final MethodpreferredLocations(split: Partition): Seq[String]preferredLocations requests CheckpointRDD for placement preferences (if the RDD is checkpointed) or calculates them itself.
|
Note
|
getPreferredLocations defines no placement preferences by default. |
|
Note
|
The other usages are to define the locations by custom RDDs, e.g.
|
getNumPartitions MethodgetNumPartitions: IntgetNumPartitions gives the number of partitions of a RDD.
scala> sc.textFile("README.md").getNumPartitions
res0: Int = 2
scala> sc.textFile("README.md", 5).getNumPartitions
res1: Int = 5computeOrReadCheckpoint MethodcomputeOrReadCheckpoint(split: Partition, context: TaskContext): Iterator[T]computeOrReadCheckpoint reads split partition from a checkpoint (if available already) or computes it yourself.
|
Note
|
computeOrReadCheckpoint is a private[spark] method.
|
|
Note
|
computeOrReadCheckpoint is used when RDD computes records for a partition or getOrCompute.
|
iterator Final Methoditerator(split: Partition, context: TaskContext): Iterator[T]iterator gets (or computes) split partition when cached or computes it (possibly by reading from checkpoint).
|
Note
|
iterator is a final method that, despite being public, considered private and only available for implementing custom RDDs.
|
getOrCompute MethodgetOrCompute(partition: Partition, context: TaskContext): Iterator[T]|
Caution
|
FIXME |
getOrCompute requests BlockManager for a block and returns a InterruptibleIterator.
|
Note
|
InterruptibleIterator delegates to a wrapped Iterator and allows for task killing functionality.
|
|
Note
|
getOrCompute is called on Spark executors.
|
Internally, getOrCompute creates a RDDBlockId (for the partition in the RDD) that is then used to retrieve it from BlockManager or compute, persist and return its values.
|
Note
|
getOrCompute is a private[spark] method that is exclusively used when iterating over partition when a RDD is cached.
|
dependencies Final Template Methoddependencies: Seq[Dependency[_]]dependencies returns the dependencies of a RDD.
|
Note
|
dependencies is a final method that no class in Spark can ever override.
|
Internally, dependencies checks out whether the RDD is checkpointed and acts accordingly.
For a RDD being checkpointed, dependencies returns a single-element collection with a OneToOneDependency.
For a non-checkpointed RDD, dependencies collection is computed using getDependencies method.
|
Note
|
getDependencies method is an abstract method that custom RDDs are required to provide.
|