BypassMergeSortShuffleWriter
BypassMergeSortShuffleWriter is a ShuffleWriter that ShuffleMapTask uses to write records into one single shuffle block data file when the task runs for a ShuffleDependency.
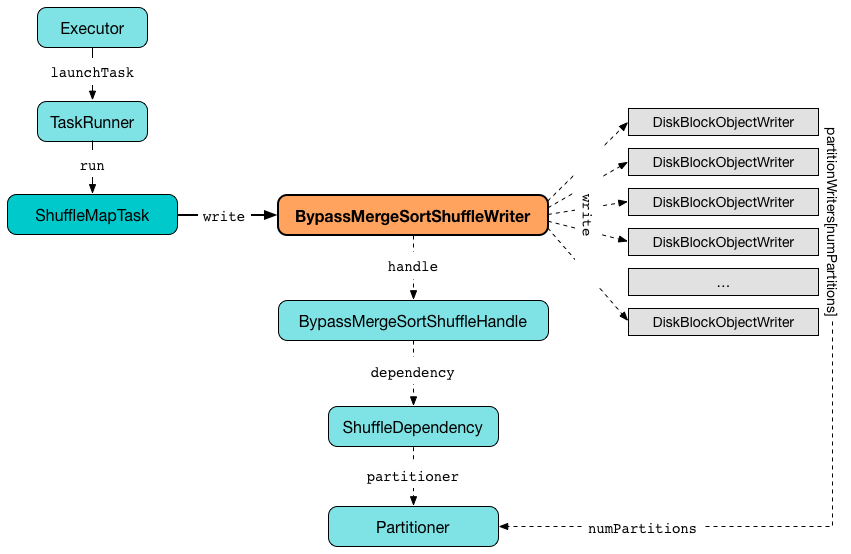
Figure 1. BypassMergeSortShuffleWriter writing records (for ShuffleMapTask) using DiskBlockObjectWriters
BypassMergeSortShuffleWriter is created exclusively when SortShuffleManager selects a ShuffleWriter (for a BypassMergeSortShuffleHandle).
|
Tip
|
Review the conditions SortShuffleManager uses to select BypassMergeSortShuffleHandle for a ShuffleHandle.
|
| Name | Description |
|---|---|
Initialized when Used when |
|
MapStatus that Initialized every time Used when |
|
Temporary array of partition lengths after records are written to a shuffle system. Initialized every time |
|
Internal flag that controls the use of Java New I/O when Specified when |
|
Tip
|
Enable Add the following line to Refer to Logging. |
Creating BypassMergeSortShuffleWriter Instance
BypassMergeSortShuffleWriter takes the following when created:
BypassMergeSortShuffleWriter uses spark.shuffle.file.buffer (for fileBufferSize as 32k by default) and spark.file.transferTo (for transferToEnabled internal flag which is enabled by default) Spark properties.
BypassMergeSortShuffleWriter initializes the internal registries and counters.
Writing Records (Into One Single Shuffle Block Data File) — write Method
void write(Iterator<Product2<K, V>> records) throws IOException|
Note
|
write is a part of ShuffleWriter contract to write a sequence of records to a shuffle system.
|
Internally, when the input records iterator has no more records, write creates an empty partitionLengths internal array of numPartitions size.
write then requests the internal IndexShuffleBlockResolver to write shuffle index and data files (with dataTmp as null) and sets the internal mapStatus (with the address of BlockManager in use and partitionLengths).
However, when there are records to write, write creates a new Serializer.
|
Note
|
Serializer was specified when BypassMergeSortShuffleWriter was created and is exactly the Serializer of the ShuffleDependency.
|
write initializes partitionWriters internal array of DiskBlockObjectWriters for every partition.
|
Note
|
write uses BlockManager to access DiskBlockManager. BlockManager was specified when BypassMergeSortShuffleWriter was created.
|
write requests BlockManager for a DiskBlockObjectWriter (for the temporary blockId and file, SerializerInstance, fileBufferSize and writeMetrics).
After DiskBlockObjectWriters were created, write increments shuffle write time.
write initializes partitionWriterSegments with FileSegment for every partition.
write takes records serially, i.e. record by record, and, after computing the partition for a key, requests the corresponding DiskBlockObjectWriter to write them.
|
Note
|
write uses partitionWriters internal array of DiskBlockObjectWriter indexed by partition number.
|
|
Note
|
write uses the Partitioner from the ShuffleDependency for which BypassMergeSortShuffleWriter was created.
|
|
Note
|
write initializes partitionWriters with numPartitions number of DiskBlockObjectWriters.
|
After all the records have been written, write requests every DiskBlockObjectWriter to commitAndGet and saves the commit results in partitionWriterSegments. write closes every DiskBlockObjectWriter.
write requests IndexShuffleBlockResolver for the shuffle block data file for shuffleId and mapId.
|
Note
|
IndexShuffleBlockResolver was defined when BypassMergeSortShuffleWriter was created.
|
write creates a temporary shuffle block data file and writes the per-partition shuffle files to it.
|
Note
|
This is the moment when BypassMergeSortShuffleWriter concatenates per-partition shuffle file segments into one single map shuffle data file.
|
In the end, write requests IndexShuffleBlockResolver to write shuffle index and data files for the shuffleId and mapId (with partitionLengths and the temporary file) and creates a new mapStatus (with the location of the BlockManager and partitionLengths).
Concatenating Per-Partition Files Into Single File (and Tracking Write Time) — writePartitionedFile Internal Method
long[] writePartitionedFile(File outputFile) throws IOExceptionwritePartitionedFile creates a file output stream for the input outputFile in append mode.
|
Note
|
writePartitionedFile uses Java’s java.io.FileOutputStream to create a file output stream.
|
writePartitionedFile starts tracking write time (as writeStartTime).
For every numPartitions partition, writePartitionedFile takes the file from the FileSegment (from partitionWriterSegments) and creates a file input stream to read raw bytes.
|
Note
|
writePartitionedFile uses Java’s java.io.FileInputStream to create a file input stream.
|
writePartitionedFile then copies the raw bytes from each partition segment input stream to outputFile (possibly using Java New I/O per transferToEnabled flag set when BypassMergeSortShuffleWriter was created) and records the length of the shuffle data file (in lengths internal array).
|
Note
|
transferToEnabled is controlled by spark.file.transferTo Spark property and is enabled (i.e. true) by default.
|
In the end, writePartitionedFile increments shuffle write time, clears partitionWriters array and returns the lengths of the shuffle data files per partition.
|
Note
|
writePartitionedFile uses ShuffleWriteMetrics to track shuffle write time that was created when BypassMergeSortShuffleWriter was created.
|
|
Note
|
writePartitionedFile is used exclusively when BypassMergeSortShuffleWriter writes records.
|
Copying Raw Bytes Between Input Streams (Possibly Using Java New I/O) — Utils.copyStream Method
copyStream(
in: InputStream,
out: OutputStream,
closeStreams: Boolean = false,
transferToEnabled: Boolean = false): LongcopyStream branches off depending on the type of in and out streams, i.e. whether they are both FileInputStream with transferToEnabled input flag is enabled.
If they are both FileInputStream with transferToEnabled enabled, copyStream gets their FileChannels and transfers bytes from the input file to the output file and counts the number of bytes, possibly zero, that were actually transferred.
|
Note
|
copyStream uses Java’s java.nio.channels.FileChannel to manage file channels.
|
If either in and out input streams are not FileInputStream or transferToEnabled flag is disabled (default), copyStream reads data from in to write to out and counts the number of bytes written.
copyStream can optionally close in and out streams (depending on the input closeStreams — disabled by default).
|
Note
|
Utils.copyStream is used when BypassMergeSortShuffleWriter writes records into one single shuffle block data file (among other places).
|
|
Note
|
Utils.copyStream is here temporarily (until I find a better place).
|
|
Tip
|
Visit the official web site of JSR 51: New I/O APIs for the Java Platform and read up on java.nio package. |