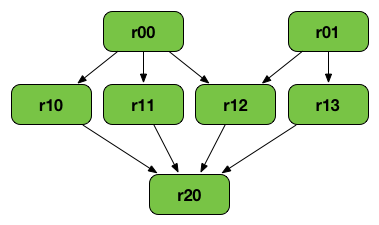
RDD Lineage — Logical Execution Plan
RDD Lineage (aka RDD operator graph or RDD dependency graph) is a graph of all the parent RDDs of a RDD. It is built as a result of applying transformations to the RDD and creates a logical execution plan.
|
Note
|
The execution DAG or physical execution plan is the DAG of stages. |
|
Note
|
The following diagram uses cartesian or zip for learning purposes only. You may use other operators to build a RDD graph.
|
Figure 1. RDD lineage
The above RDD graph could be the result of the following series of transformations:
val r00 = sc.parallelize(0 to 9)
val r01 = sc.parallelize(0 to 90 by 10)
val r10 = r00 cartesian r01
val r11 = r00.map(n => (n, n))
val r12 = r00 zip r01
val r13 = r01.keyBy(_ / 20)
val r20 = Seq(r11, r12, r13).foldLeft(r10)(_ union _)A RDD lineage graph is hence a graph of what transformations need to be executed after an action has been called.
You can learn about a RDD lineage graph using RDD.toDebugString method.
Logical Execution Plan
Logical Execution Plan starts with the earliest RDDs (those with no dependencies on other RDDs or reference cached data) and ends with the RDD that produces the result of the action that has been called to execute.
|
Note
|
A logical plan, i.e. a DAG, is materialized and executed when SparkContext is requested to run a Spark job.
|
Getting RDD Lineage Graph — toDebugString Method
toDebugString: StringYou can learn about a RDD lineage graph using toDebugString method.
scala> val wordCount = sc.textFile("README.md").flatMap(_.split("\\s+")).map((_, 1)).reduceByKey(_ + _)
wordCount: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[21] at reduceByKey at <console>:24
scala> wordCount.toDebugString
res13: String =
(2) ShuffledRDD[21] at reduceByKey at <console>:24 []
+-(2) MapPartitionsRDD[20] at map at <console>:24 []
| MapPartitionsRDD[19] at flatMap at <console>:24 []
| README.md MapPartitionsRDD[18] at textFile at <console>:24 []
| README.md HadoopRDD[17] at textFile at <console>:24 []toDebugString uses indentations to indicate a shuffle boundary.
The numbers in round brackets show the level of parallelism at each stage, e.g. (2) in the above output.
scala> wordCount.getNumPartitions
res14: Int = 2With spark.logLineage property enabled, toDebugString is included when executing an action.
$ ./bin/spark-shell --conf spark.logLineage=true
scala> sc.textFile("README.md", 4).count
...
15/10/17 14:46:42 INFO SparkContext: Starting job: count at <console>:25
15/10/17 14:46:42 INFO SparkContext: RDD's recursive dependencies:
(4) MapPartitionsRDD[1] at textFile at <console>:25 []
| README.md HadoopRDD[0] at textFile at <console>:25 []Settings
| Spark Property | Default Value | Description |
|---|---|---|
|
When enabled (i.e. |