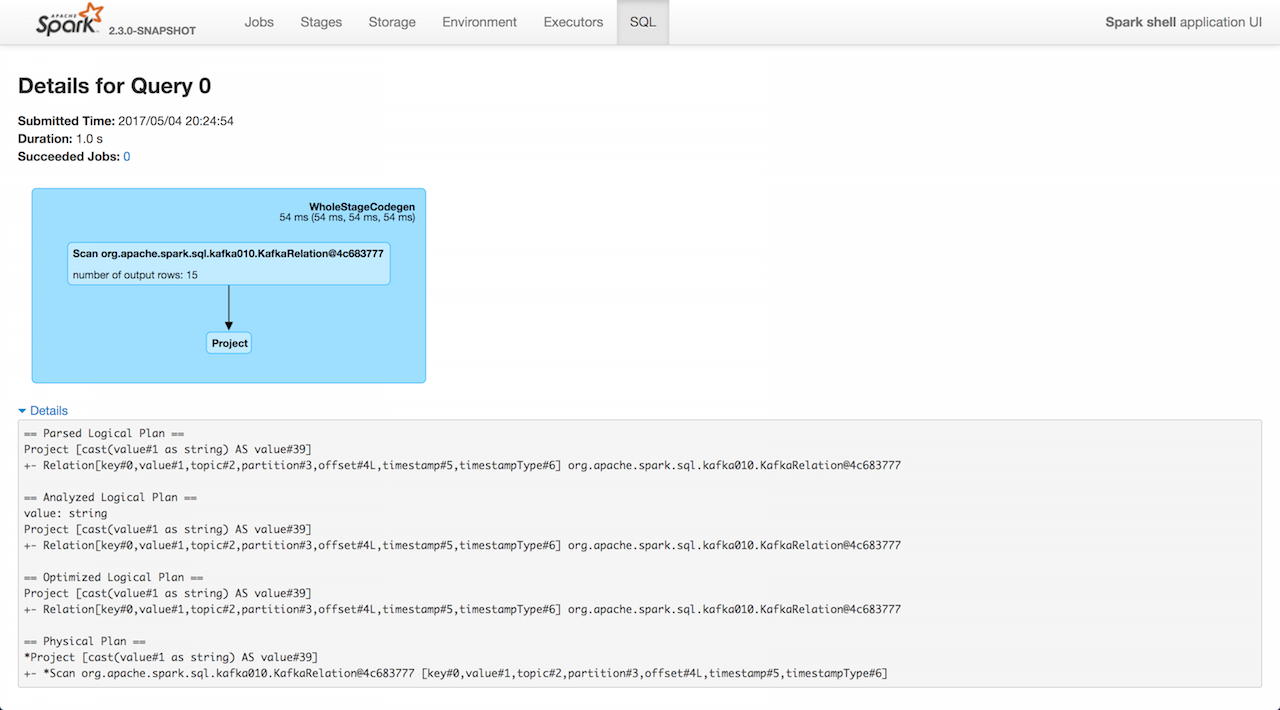
KafkaWriter — Writing Dataset to Kafka
KafkaWriter is used to write the result of a batch or structured streaming query to Apache Kafka (with a new execution id attached so you can see the execution in web UI’s SQL tab).
Figure 1. KafkaWriter (write) in web UI
KafkaWriter makes sure that the schema of the Dataset to write records of contains:
-
Required topic as a field of type
StringTypeor specified explicitly -
Required value as a field of type
StringTypeorBinaryType -
Optional key as a field of type
StringTypeorBinaryType
// KafkaWriter is a private `kafka010` package object
// and so the code to use it should also be in the same package
// BEGIN: Use `:paste -raw` in spark-shell
package org.apache.spark.sql.kafka010
object PublicKafkaWriter {
import org.apache.spark.sql.execution.QueryExecution
def validateQuery(
queryExecution: QueryExecution,
kafkaParameters: Map[String, Object],
topic: Option[String] = None): Unit = {
import scala.collection.JavaConversions.mapAsJavaMap
KafkaWriter.validateQuery(queryExecution, kafkaParameters, topic)
}
}
// END
import org.apache.spark.sql.kafka010.{PublicKafkaWriter => PKW}
val spark: SparkSession = ...
val q = spark.range(1).select('id)
scala> PKW.validateQuery(
queryExecution = q.queryExecution,
kafkaParameters = Map.empty[String, Object])
org.apache.spark.sql.AnalysisException: topic option required when no 'topic' attribute is present. Use the topic option for setting a topic.;
at org.apache.spark.sql.kafka010.KafkaWriter$$anonfun$2.apply(KafkaWriter.scala:53)
at org.apache.spark.sql.kafka010.KafkaWriter$$anonfun$2.apply(KafkaWriter.scala:52)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.kafka010.KafkaWriter$.validateQuery(KafkaWriter.scala:51)
at org.apache.spark.sql.kafka010.PublicKafkaWriter$.validateQuery(<pastie>:10)
... 50 elided Writing Query Results to Kafka — write Method
write(
sparkSession: SparkSession,
queryExecution: QueryExecution,
kafkaParameters: ju.Map[String, Object],
topic: Option[String] = None): Unitwrite creates and executes a KafkaWriteTask per partition of the QueryExecution's RDD (with a new execution id attached so you can see the execution in web UI’s SQL tab).
|
Note
|
|
Validating QueryExecution — validateQuery Method
validateQuery(
queryExecution: QueryExecution,
kafkaParameters: java.util.Map[String, Object],
topic: Option[String] = None): UnitvalidateQuery validates the schema of the input analyzed QueryExecution, i.e.
-
Whether the required topic is available as a field of type
StringTypein the schema or as the inputtopic -
Whether the optional key is available as a field of type
StringTypeorBinaryTypein the schema -
Whether the required value is available as a field of type
StringTypeorBinaryTypein the schema
|
Note
|
validateQuery is used exclusively when KafkaWriter writes the result of a query to Kafka.
|