DAGScheduler — Stage-Oriented Scheduler
|
Note
|
The introduction that follows was highly influenced by the scaladoc of org.apache.spark.scheduler.DAGScheduler. As DAGScheduler is a private class it does not appear in the official API documentation. You are strongly encouraged to read the sources and only then read this and the related pages afterwards. "Reading the sources", I say?! Yes, I am kidding! |
Introduction
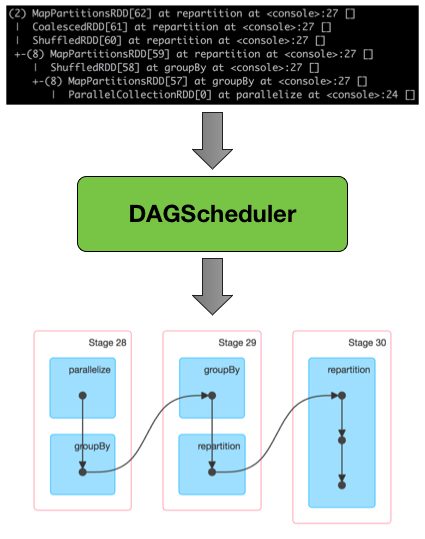
DAGScheduler is the scheduling layer of Apache Spark that implements stage-oriented scheduling. It transforms a logical execution plan (i.e. RDD lineage of dependencies built using RDD transformations) to a physical execution plan (using stages).
Figure 1.
DAGScheduler Transforming RDD Lineage Into Stage DAGAfter an action has been called, SparkContext hands over a logical plan to DAGScheduler that it in turn translates to a set of stages that are submitted as TaskSets for execution (see Execution Model).
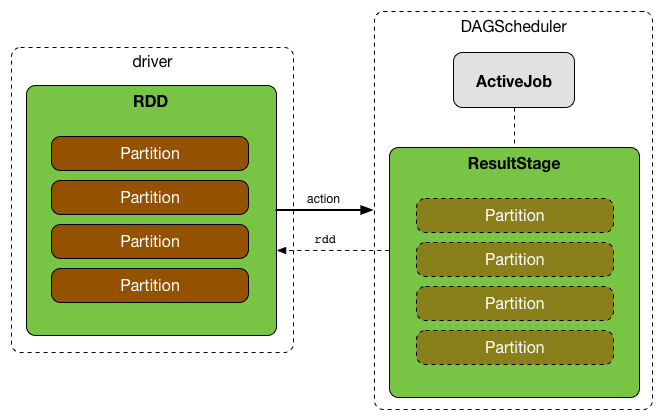
Figure 2. Executing action leads to new ResultStage and ActiveJob in DAGScheduler
The fundamental concepts of DAGScheduler are jobs and stages (refer to Jobs and Stages respectively) that it tracks through internal registries and counters.
DAGScheduler works solely on the driver and is created as part of SparkContext’s initialization (right after TaskScheduler and SchedulerBackend are ready).
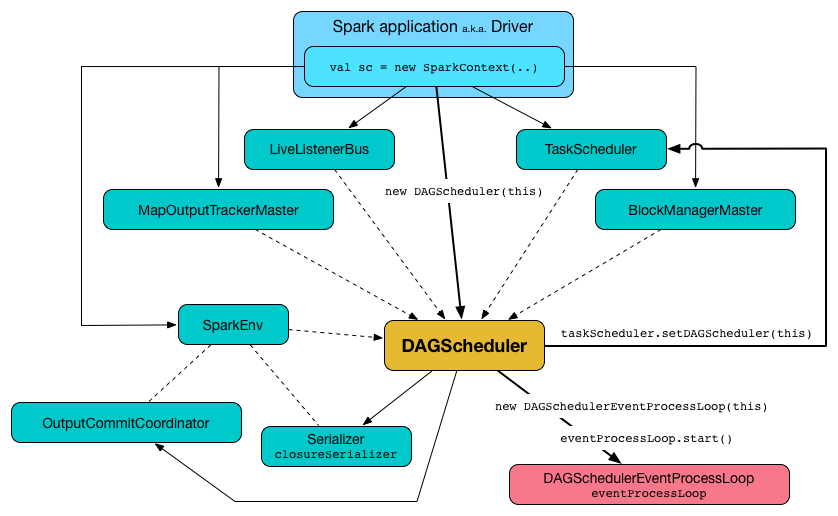
Figure 3. DAGScheduler as created by SparkContext with other services
DAGScheduler does three things in Spark (thorough explanations follow):
-
Computes an execution DAG, i.e. DAG of stages, for a job.
-
Determines the preferred locations to run each task on.
-
Handles failures due to shuffle output files being lost.
DAGScheduler computes a directed acyclic graph (DAG) of stages for each job, keeps track of which RDDs and stage outputs are materialized, and finds a minimal schedule to run jobs. It then submits stages to TaskScheduler.
In addition to coming up with the execution DAG, DAGScheduler also determines the preferred locations to run each task on, based on the current cache status, and passes the information to TaskScheduler.
DAGScheduler tracks which RDDs are cached (or persisted) to avoid "recomputing" them, i.e. redoing the map side of a shuffle. DAGScheduler remembers what ShuffleMapStages have already produced output files (that are stored in BlockManagers).
DAGScheduler is only interested in cache location coordinates, i.e. host and executor id, per partition of a RDD.
|
Caution
|
FIXME: A diagram, please |
Furthermore, it handles failures due to shuffle output files being lost, in which case old stages may need to be resubmitted. Failures within a stage that are not caused by shuffle file loss are handled by the TaskScheduler itself, which will retry each task a small number of times before cancelling the whole stage.
DAGScheduler uses an event queue architecture in which a thread can post DAGSchedulerEvent events, e.g. a new job or stage being submitted, that DAGScheduler reads and executes sequentially. See the section Internal Event Loop - dag-scheduler-event-loop.
DAGScheduler runs stages in topological order.
| Name | Initial Value | Description |
|---|---|---|
| Name | Description |
|---|---|
|
|
Block locations per RDD and partition. Uses TaskLocation that includes a host name and an executor id on that host (as The keys are RDDs (their ids) and the values are arrays indexed by partition numbers. Each entry is a set of block locations where a RDD partition is cached, i.e. the BlockManagers of the blocks. Initialized empty when Used when |
|
The lookup table of lost executors and the epoch of the event. |
|
Stages that failed due to fetch failures (when a task fails with |
|
The lookup table of |
|
The lookup table of all stages per |
|
The next job id counting from Used when |
|
The next stage id counting from Used when |
|
The set of stages that are currently "running". A stage is added when submitMissingTasks gets executed (without first checking if the stage has not already been added). |
|
The lookup table of ShuffleMapStages per ShuffleDependency. |
|
The lookup table for stages per their ids. Used when |
|
The stages with parents to be computed |
|
Tip
|
Enable Add the following line to Refer to Logging. |
DAGScheduler uses SparkContext, TaskScheduler, LiveListenerBus, MapOutputTracker and BlockManager for its services. However, at the very minimum, DAGScheduler takes a SparkContext only (and requests SparkContext for the other services).
DAGScheduler reports metrics about its execution (refer to the section Metrics).
When DAGScheduler schedules a job as a result of executing an action on a RDD or calling SparkContext.runJob() method directly, it spawns parallel tasks to compute (partial) results per partition.
Running Approximate Job — runApproximateJob Method
|
Caution
|
FIXME |
createResultStage Internal Method
createResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage|
Caution
|
FIXME |
updateJobIdStageIdMaps Method
|
Caution
|
FIXME |
Creating DAGScheduler Instance
DAGScheduler takes the following when created:
DAGScheduler initializes the internal registries and counters.
DAGScheduler sets itself in the given TaskScheduler and in the end starts DAGScheduler Event Bus.
|
Note
|
DAGScheduler can reference all the services through a single SparkContext with or without specifying explicit TaskScheduler.
|
LiveListenerBus Event Bus for SparkListenerEvents — listenerBus Property
listenerBus: LiveListenerBuslistenerBus is a LiveListenerBus to post scheduling events and is passed in when DAGScheduler is created.
executorHeartbeatReceived Method
executorHeartbeatReceived(
execId: String,
accumUpdates: Array[(Long, Int, Int, Seq[AccumulableInfo])],
blockManagerId: BlockManagerId): BooleanexecutorHeartbeatReceived posts a SparkListenerExecutorMetricsUpdate (to listenerBus) and informs BlockManagerMaster that blockManagerId block manager is alive (by posting BlockManagerHeartbeat).
|
Note
|
executorHeartbeatReceived is called when TaskSchedulerImpl handles executorHeartbeatReceived.
|
Cleaning Up After ActiveJob and Independent Stages — cleanupStateForJobAndIndependentStages Method
cleanupStateForJobAndIndependentStages(job: ActiveJob): UnitcleanupStateForJobAndIndependentStages cleans up the state for job and any stages that are not part of any other job.
cleanupStateForJobAndIndependentStages looks the job up in the internal jobIdToStageIds registry.
If no stages are found, the following ERROR is printed out to the logs:
ERROR No stages registered for job [jobId]Oterwise, cleanupStateForJobAndIndependentStages uses stageIdToStage registry to find the stages (the real objects not ids!).
For each stage, cleanupStateForJobAndIndependentStages reads the jobs the stage belongs to.
If the job does not belong to the jobs of the stage, the following ERROR is printed out to the logs:
ERROR Job [jobId] not registered for stage [stageId] even though that stage was registered for the jobIf the job was the only job for the stage, the stage (and the stage id) gets cleaned up from the registries, i.e. runningStages, shuffleIdToMapStage, waitingStages, failedStages and stageIdToStage.
While removing from runningStages, you should see the following DEBUG message in the logs:
DEBUG Removing running stage [stageId]While removing from waitingStages, you should see the following DEBUG message in the logs:
DEBUG Removing stage [stageId] from waiting set.While removing from failedStages, you should see the following DEBUG message in the logs:
DEBUG Removing stage [stageId] from failed set.After all cleaning (using stageIdToStage as the source registry), if the stage belonged to the one and only job, you should see the following DEBUG message in the logs:
DEBUG After removal of stage [stageId], remaining stages = [stageIdToStage.size]The job is removed from jobIdToStageIds, jobIdToActiveJob, activeJobs registries.
The final stage of the job is removed, i.e. ResultStage or ShuffleMapStage.
|
Note
|
cleanupStateForJobAndIndependentStages is used in handleTaskCompletion when a ResultTask has completed successfully, failJobAndIndependentStages and markMapStageJobAsFinished.
|
Marking ShuffleMapStage Job Finished — markMapStageJobAsFinished Method
markMapStageJobAsFinished(job: ActiveJob, stats: MapOutputStatistics): UnitmarkMapStageJobAsFinished marks the active job finished and notifies Spark listeners.
Internally, markMapStageJobAsFinished marks the zeroth partition finished and increases the number of tasks finished in job.
Ultimately, SparkListenerJobEnd is posted to LiveListenerBus (as listenerBus) for the job, the current time (in millis) and JobSucceeded job result.
|
Note
|
markMapStageJobAsFinished is used in handleMapStageSubmitted and handleTaskCompletion.
|
Submitting Job — submitJob method
submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U]submitJob creates a JobWaiter and posts a JobSubmitted event.
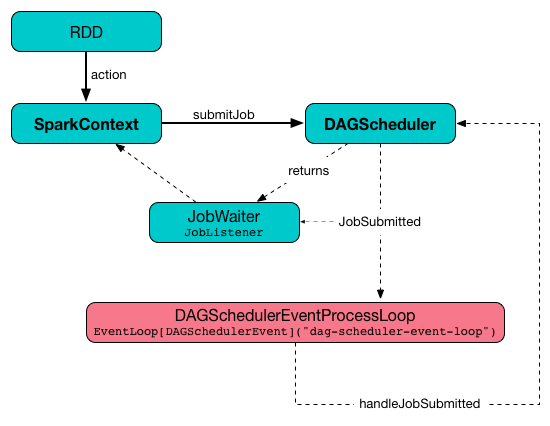
Figure 4. DAGScheduler.submitJob
Internally, submitJob does the following:
You may see a IllegalArgumentException thrown when the input partitions references partitions not in the input rdd:
Attempting to access a non-existent partition: [p]. Total number of partitions: [maxPartitions]|
Note
|
submitJob is called when SparkContext submits a job and DAGScheduler runs a job.
|
|
Note
|
submitJob assumes that the partitions of a RDD are indexed from 0 onwards in sequential order.
|
Submitting ShuffleDependency for Execution — submitMapStage Method
submitMapStage[K, V, C](
dependency: ShuffleDependency[K, V, C],
callback: MapOutputStatistics => Unit,
callSite: CallSite,
properties: Properties): JobWaiter[MapOutputStatistics]submitMapStage creates a JobWaiter (that it eventually returns) and posts a MapStageSubmitted event to DAGScheduler Event Bus).
Internally, submitMapStage increments nextJobId internal counter to get the job id.
submitMapStage then creates a JobWaiter (with the job id and with one artificial task that will however get completed only when the entire stage finishes).
submitMapStage announces the map stage submission application-wide (by posting a MapStageSubmitted to LiveListenerBus).
|
Note
|
A MapStageSubmitted holds the newly-created job id and JobWaiter with the input dependency, callSite and properties parameters.
|
submitMapStage returns the JobWaiter.
If the number of partition to compute is 0, submitMapStage throws a SparkException:
Can't run submitMapStage on RDD with 0 partitions|
Note
|
submitMapStage is used when SparkContext submits a map stage for execution.
|
Relaying Stage Cancellation From SparkContext (by Posting StageCancelled to DAGScheduler Event Bus) — cancelStage Method
cancelStage(stageId: Int)cancelJobGroup merely posts a StageCancelled event to the DAGScheduler Event Bus.
|
Note
|
cancelStage is used exclusively when SparkContext cancels a stage.
|
Relaying Job Group Cancellation From SparkContext (by Posting JobGroupCancelled to DAGScheduler Event Bus) — cancelJobGroup Method
cancelJobGroup(groupId: String): UnitcancelJobGroup prints the following INFO message to the logs followed by posting a JobGroupCancelled event to the DAGScheduler Event Bus.
INFO Asked to cancel job group [groupId]|
Note
|
cancelJobGroup is used exclusively when SparkContext cancels a job group.
|
Relaying All Jobs Cancellation From SparkContext (by Posting AllJobsCancelled to DAGScheduler Event Bus) — cancelAllJobs Method
cancelAllJobs(): UnitcancelAllJobs merely posts a AllJobsCancelled event to the DAGScheduler Event Bus.
|
Note
|
cancelAllJobs is used exclusively when SparkContext cancels all running or scheduled Spark jobs.
|
Relaying Task Started From TaskSetManager (by Posting BeginEvent to DAGScheduler Event Bus) — taskStarted Method
taskStarted(task: Task[_], taskInfo: TaskInfo)taskStarted merely posts a BeginEvent event to the DAGScheduler Event Bus.
|
Note
|
taskStarted is used exclusively when a TaskSetManager starts a task.
|
Relaying Task Fetching/Getting Result From TaskSetManager (by Posting GettingResultEvent to DAGScheduler Event Bus) — taskGettingResult Method
taskGettingResult(taskInfo: TaskInfo)taskGettingResult merely posts a GettingResultEvent event to the DAGScheduler Event Bus.
|
Note
|
taskGettingResult is used exclusively when a TaskSetManager gets notified about a task fetching result.
|
Relaying Task End From TaskSetManager (by Posting CompletionEvent to DAGScheduler Event Bus) — taskEnded Method
taskEnded(
task: Task[_],
reason: TaskEndReason,
result: Any,
accumUpdates: Map[Long, Any],
taskInfo: TaskInfo,
taskMetrics: TaskMetrics): UnittaskEnded simply posts a CompletionEvent event to the DAGScheduler Event Bus.
|
Note
|
taskEnded is used exclusively when a TaskSetManager reports task completions, i.e. success or failure.
|
|
Tip
|
Read TaskMetrics. |
Relaying TaskSet Failed From TaskSetManager (by Posting TaskSetFailed to DAGScheduler Event Bus) — taskSetFailed Method
taskSetFailed(
taskSet: TaskSet,
reason: String,
exception: Option[Throwable]): UnittaskSetFailed simply posts a TaskSetFailed to DAGScheduler Event Bus.
|
Note
|
The input arguments of taskSetFailed are exactly the arguments of TaskSetFailed.
|
|
Note
|
taskSetFailed is used exclusively when a TaskSetManager is aborted.
|
Relaying Executor Lost From TaskSchedulerImpl (by Posting ExecutorLost to DAGScheduler Event Bus) — executorLost Method
executorLost(execId: String, reason: ExecutorLossReason): UnitexecutorLost simply posts a ExecutorLost event to DAGScheduler Event Bus.
|
Note
|
executorLost is used when TaskSchedulerImpl gets task status update (and a task gets lost which is used to indicate that the executor got broken and hence should be considered lost) or executorLost.
|
Relaying Executor Added From TaskSchedulerImpl (by Posting ExecutorAdded to DAGScheduler Event Bus) — executorAdded Method
executorAdded(execId: String, host: String): UnitexecutorAdded simply posts a ExecutorAdded event to DAGScheduler Event Bus.
|
Note
|
executorAdded is used exclusively when TaskSchedulerImpl is offered resources on executors (and a new executor is found in the resource offers).
|
Relaying Job Cancellation From SparkContext or JobWaiter (by Posting JobCancelled to DAGScheduler Event Bus) — cancelJob Method
cancelJob(jobId: Int): UnitcancelJob prints the following INFO message and posts a JobCancelled to DAGScheduler Event Bus.
INFO DAGScheduler: Asked to cancel job [id]|
Note
|
cancelJob is used when SparkContext or JobWaiter cancel a Spark job.
|
Finding Or Creating Missing Direct Parent ShuffleMapStages (For ShuffleDependencies of Input RDD) — getOrCreateParentStages Internal Method
getOrCreateParentStages(rdd: RDD[_], firstJobId: Int): List[Stage]getOrCreateParentStages finds all direct parent ShuffleDependencies of the input rdd and then finds ShuffleMapStage stages for each ShuffleDependency.
|
Note
|
getOrCreateParentStages is used when DAGScheduler createShuffleMapStage and createResultStage.
|
Marking Stage Finished — markStageAsFinished Internal Method
markStageAsFinished(stage: Stage, errorMessage: Option[String] = None): Unit|
Caution
|
FIXME |
Running Job — runJob Method
runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): UnitrunJob submits an action job to the DAGScheduler and waits for a result.
When the job succeeds, you should see the following INFO message in the logs:
INFO Job [jobId] finished: [callSite], took [time] sWhen the job fails, you should see the following INFO message in the logs and the exception (that led to the failure) is thrown.
INFO Job [jobId] failed: [callSite], took [time] s|
Note
|
runJob is used when SparkContext runs a job.
|
Finding or Creating New ShuffleMapStages for ShuffleDependency — getOrCreateShuffleMapStage Internal Method
getOrCreateShuffleMapStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStagegetOrCreateShuffleMapStage finds or creates the ShuffleMapStage for the input ShuffleDependency.
Internally, getOrCreateShuffleMapStage finds the ShuffleDependency in shuffleIdToMapStage internal registry and returns one when found.
If no ShuffleDependency was available, getOrCreateShuffleMapStage finds all the missing shuffle dependencies and creates corresponding ShuffleMapStage stages (including one for the input shuffleDep).
|
Note
|
All the new ShuffleMapStage stages are associated with the input firstJobId.
|
|
Note
|
getOrCreateShuffleMapStage is used when DAGScheduler finds or creates missing direct parent ShuffleMapStages (for ShuffleDependencies of given RDD), getMissingParentStages (for ShuffleDependencies), is notified that ShuffleDependency was submitted, and checks if a stage depends on another.
|
Creating ShuffleMapStage for ShuffleDependency (Copying Shuffle Map Output Locations From Previous Jobs) — createShuffleMapStage Method
createShuffleMapStage(
shuffleDep: ShuffleDependency[_, _, _],
jobId: Int): ShuffleMapStagecreateShuffleMapStage creates a ShuffleMapStage for the input ShuffleDependency and jobId (of a ActiveJob) possibly copying shuffle map output locations from previous jobs to avoid recomputing records.
|
Note
|
When a ShuffleMapStage is created, the id is generated (using nextStageId internal counter), rdd is from ShuffleDependency, numTasks is the number of partitions in the RDD, all parents are looked up (and possibly created), the jobId is given, callSite is the creationSite of the RDD, and shuffleDep is the input ShuffleDependency.
|
Internally, createShuffleMapStage first finds or creates missing parent ShuffleMapStage stages of the associated RDD.
|
Note
|
ShuffleDependency is associated with exactly one RDD[Product2[K, V]].
|
createShuffleMapStage creates a ShuffleMapStage (with the stage id from nextStageId internal counter).
|
Note
|
The RDD of the new ShuffleMapStage is from the input ShuffleDependency.
|
createShuffleMapStage registers the ShuffleMapStage in stageIdToStage and shuffleIdToMapStage internal registries.
createShuffleMapStage calls updateJobIdStageIdMaps.
If MapOutputTrackerMaster tracks the input ShuffleDependency (because other jobs have already computed it), createShuffleMapStage requests the serialized ShuffleMapStage outputs, deserializes them and registers with the new ShuffleMapStage.
|
Note
|
MapOutputTrackerMaster was defined when DAGScheduler was created.
|
Figure 5.
DAGScheduler Asks MapOutputTrackerMaster Whether Shuffle Map Output Is Already TrackedIf however MapOutputTrackerMaster does not track the input ShuffleDependency, you should see the following INFO message in the logs and createShuffleMapStage registers the ShuffleDependency with MapOutputTrackerMaster.
INFO Registering RDD [id] ([creationSite])createShuffleMapStage returns the new ShuffleMapStage.
|
Note
|
createShuffleMapStage is executed only when DAGScheduler finds or creates parent ShuffleMapStage stages for a ShuffleDependency.
|
Clearing Cache of RDD Block Locations — clearCacheLocs Internal Method
clearCacheLocs(): UnitclearCacheLocs clears the internal registry of the partition locations per RDD.
|
Note
|
DAGScheduler clears the cache while resubmitting failed stages, and as a result of JobSubmitted, MapStageSubmitted, CompletionEvent, ExecutorLost events.
|
Finding Missing ShuffleDependencies For RDD — getMissingAncestorShuffleDependencies Internal Method
getMissingAncestorShuffleDependencies(rdd: RDD[_]): Stack[ShuffleDependency[_, _, _]]getMissingAncestorShuffleDependencies finds all missing shuffle dependencies for the given RDD traversing its dependency chain (aka RDD lineage).
|
Note
|
A missing shuffle dependency of a RDD is a dependency not registered in shuffleIdToMapStage internal registry.
|
Internally, getMissingAncestorShuffleDependencies finds direct parent shuffle dependencies of the input RDD and collects the ones that are not registered in shuffleIdToMapStage internal registry. It repeats the process for the RDDs of the parent shuffle dependencies.
|
Note
|
getMissingAncestorShuffleDependencies is used when DAGScheduler finds all ShuffleMapStage stages for a ShuffleDependency.
|
Finding Direct Parent Shuffle Dependencies of RDD — getShuffleDependencies Internal Method
getShuffleDependencies(rdd: RDD[_]): HashSet[ShuffleDependency[_, _, _]]getShuffleDependencies finds direct parent shuffle dependencies for the given RDD.
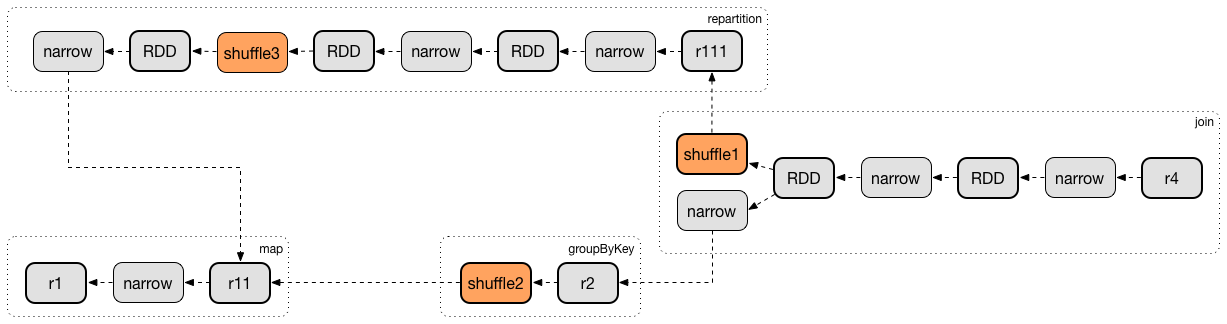
Figure 6. getShuffleDependencies Finds Direct Parent ShuffleDependencies (shuffle1 and shuffle2)
Internally, getShuffleDependencies takes the direct shuffle dependencies of the input RDD and direct shuffle dependencies of all the parent non-ShuffleDependencies in the dependency chain (aka RDD lineage).
|
Note
|
getShuffleDependencies is used when DAGScheduler finds or creates missing direct parent ShuffleMapStages (for ShuffleDependencies of given RDD) and finds all missing shuffle dependencies for a given RDD.
|
Failing Job and Independent Single-Job Stages — failJobAndIndependentStages Internal Method
failJobAndIndependentStages(
job: ActiveJob,
failureReason: String,
exception: Option[Throwable] = None): UnitThe internal failJobAndIndependentStages method fails the input job and all the stages that are only used by the job.
Internally, failJobAndIndependentStages uses jobIdToStageIds internal registry to look up the stages registered for the job.
If no stages could be found, you should see the following ERROR message in the logs:
ERROR No stages registered for job [id]Otherwise, for every stage, failJobAndIndependentStages finds the job ids the stage belongs to.
If no stages could be found or the job is not referenced by the stages, you should see the following ERROR message in the logs:
ERROR Job [id] not registered for stage [id] even though that stage was registered for the jobOnly when there is exactly one job registered for the stage and the stage is in RUNNING state (in runningStages internal registry), TaskScheduler is requested to cancel the stage’s tasks and marks the stage finished.
|
Note
|
failJobAndIndependentStages is called from handleJobCancellation and abortStage.
|
|
Note
|
failJobAndIndependentStages uses jobIdToStageIds, stageIdToStage, and runningStages internal registries.
|
Aborting Stage — abortStage Internal Method
abortStage(
failedStage: Stage,
reason: String,
exception: Option[Throwable]): UnitabortStage is an internal method that finds all the active jobs that depend on the failedStage stage and fails them.
Internally, abortStage looks the failedStage stage up in the internal stageIdToStage registry and exits if there the stage was not registered earlier.
If it was, abortStage finds all the active jobs (in the internal activeJobs registry) with the final stage depending on the failedStage stage.
At this time, the completionTime property (of the failed stage’s StageInfo) is assigned to the current time (millis).
All the active jobs that depend on the failed stage (as calculated above) and the stages that do not belong to other jobs (aka independent stages) are failed (with the failure reason being "Job aborted due to stage failure: [reason]" and the input exception).
If there are no jobs depending on the failed stage, you should see the following INFO message in the logs:
INFO Ignoring failure of [failedStage] because all jobs depending on it are done|
Note
|
abortStage is used to handle TaskSetFailed event, when submitting a stage with no active job
|
Checking Out Stage Dependency on Given Stage — stageDependsOn Method
stageDependsOn(stage: Stage, target: Stage): BooleanstageDependsOn compares two stages and returns whether the stage depends on target stage (i.e. true) or not (i.e. false).
|
Note
|
A stage A depends on stage B if B is among the ancestors of A.
|
Internally, stageDependsOn walks through the graph of RDDs of the input stage. For every RDD in the RDD’s dependencies (using RDD.dependencies) stageDependsOn adds the RDD of a NarrowDependency to a stack of RDDs to visit while for a ShuffleDependency it finds ShuffleMapStage stages for a ShuffleDependency for the dependency and the stage's first job id that it later adds to a stack of RDDs to visit if the map stage is ready, i.e. all the partitions have shuffle outputs.
After all the RDDs of the input stage are visited, stageDependsOn checks if the target's RDD is among the RDDs of the stage, i.e. whether the stage depends on target stage.
dag-scheduler-event-loop — DAGScheduler Event Bus
eventProcessLoop is DAGScheduler’s event bus to which Spark (by submitJob) posts jobs to schedule their execution. Later on, TaskSetManager talks back to DAGScheduler to inform about the status of the tasks using the same "communication channel".
It allows Spark to release the current thread when posting happens and let the event loop handle events on a separate thread - asynchronously.
…IMAGE…FIXME
|
Caution
|
FIXME statistics? MapOutputStatistics?
|
Submitting Waiting Child Stages for Execution — submitWaitingChildStages Internal Method
submitWaitingChildStages(parent: Stage): UnitsubmitWaitingChildStages submits for execution all waiting stages for which the input parent Stage is the direct parent.
|
Note
|
Waiting stages are the stages registered in waitingStages internal registry.
|
When executed, you should see the following TRACE messages in the logs:
TRACE DAGScheduler: Checking if any dependencies of [parent] are now runnable
TRACE DAGScheduler: running: [runningStages]
TRACE DAGScheduler: waiting: [waitingStages]
TRACE DAGScheduler: failed: [failedStages]submitWaitingChildStages finds child stages of the input parent stage, removes them from waitingStages internal registry, and submits one by one sorted by their job ids.
|
Note
|
submitWaitingChildStages is executed when DAGScheduler submits missing tasks for stage and handles successful ShuffleMapTask completion.
|
Submitting Stage or Its Missing Parents for Execution — submitStage Internal Method
submitStage(stage: Stage)submitStage is an internal method that DAGScheduler uses to submit the input stage or its missing parents (if there any stages not computed yet before the input stage could).
|
Note
|
submitStage is also used to resubmit failed stages.
|
submitStage recursively submits any missing parents of the stage.
Internally, submitStage first finds the earliest-created job id that needs the stage.
|
Note
|
A stage itself tracks the jobs (their ids) it belongs to (using the internal jobIds registry).
|
The following steps depend on whether there is a job or not.
If there are no jobs that require the stage, submitStage aborts it with the reason:
No active job for stage [id]If however there is a job for the stage, you should see the following DEBUG message in the logs:
DEBUG DAGScheduler: submitStage([stage])submitStage checks the status of the stage and continues when it was not recorded in waiting, running or failed internal registries. It simply exits otherwise.
With the stage ready for submission, submitStage calculates the list of missing parent stages of the stage (sorted by their job ids). You should see the following DEBUG message in the logs:
DEBUG DAGScheduler: missing: [missing]When the stage has no parent stages missing, you should see the following INFO message in the logs:
INFO DAGScheduler: Submitting [stage] ([stage.rdd]), which has no missing parentssubmitStage submits the stage (with the earliest-created job id) and finishes.
If however there are missing parent stages for the stage, submitStage submits all the parent stages, and the stage is recorded in the internal waitingStages registry.
|
Note
|
submitStage is executed when DAGScheduler submits missing parent map stages (of a stage) recursively or waiting child stages, resubmits failed stages, and handles JobSubmitted, MapStageSubmitted, or CompletionEvent events.
|
Fault recovery - stage attempts
A single stage can be re-executed in multiple attempts due to fault recovery. The number of attempts is configured (FIXME).
If TaskScheduler reports that a task failed because a map output file from a previous stage was lost, the DAGScheduler resubmits the lost stage. This is detected through a CompletionEvent with FetchFailed, or an ExecutorLost event. DAGScheduler will wait a small amount of time to see whether other nodes or tasks fail, then resubmit TaskSets for any lost stage(s) that compute the missing tasks.
Please note that tasks from the old attempts of a stage could still be running.
A stage object tracks multiple StageInfo objects to pass to Spark listeners or the web UI.
The latest StageInfo for the most recent attempt for a stage is accessible through latestInfo.
Preferred Locations
DAGScheduler computes where to run each task in a stage based on the preferred locations of its underlying RDDs, or the location of cached or shuffle data.
Adaptive Query Planning / Adaptive Scheduling
See SPARK-9850 Adaptive execution in Spark for the design document. The work is currently in progress.
DAGScheduler.submitMapStage method is used for adaptive query planning, to run map stages and look at statistics about their outputs before submitting downstream stages.
ScheduledExecutorService daemon services
DAGScheduler uses the following ScheduledThreadPoolExecutors (with the policy of removing cancelled tasks from a work queue at time of cancellation):
-
dag-scheduler-message- a daemon thread pool usingj.u.c.ScheduledThreadPoolExecutorwith core pool size1. It is used to post a ResubmitFailedStages event whenFetchFailedis reported.
They are created using ThreadUtils.newDaemonSingleThreadScheduledExecutor method that uses Guava DSL to instantiate a ThreadFactory.
Finding Missing Parent ShuffleMapStages For Stage — getMissingParentStages Internal Method
getMissingParentStages(stage: Stage): List[Stage]getMissingParentStages finds missing parent ShuffleMapStages in the dependency graph of the input stage (using the breadth-first search algorithm).
Internally, getMissingParentStages starts with the stage's RDD and walks up the tree of all parent RDDs to find uncached partitions.
|
Note
|
A Stage tracks the associated RDD using rdd property.
|
|
Note
|
An uncached partition of a RDD is a partition that has Nil in the internal registry of partition locations per RDD (which results in no RDD blocks in any of the active BlockManagers on executors).
|
getMissingParentStages traverses the parent dependencies of the RDD and acts according to their type, i.e. ShuffleDependency or NarrowDependency.
|
Note
|
ShuffleDependency and NarrowDependency are the main top-level Dependencies. |
For each NarrowDependency, getMissingParentStages simply marks the corresponding RDD to visit and moves on to a next dependency of a RDD or works on another unvisited parent RDD.
|
Note
|
NarrowDependency is a RDD dependency that allows for pipelined execution. |
getMissingParentStages focuses on ShuffleDependency dependencies.
|
Note
|
ShuffleDependency is a RDD dependency that represents a dependency on the output of a ShuffleMapStage, i.e. shuffle map stage. |
For each ShuffleDependency, getMissingParentStages finds ShuffleMapStage stages. If the ShuffleMapStage is not available, it is added to the set of missing (map) stages.
|
Note
|
A ShuffleMapStage is available when all its partitions are computed, i.e. results are available (as blocks).
|
|
Caution
|
FIXME…IMAGE with ShuffleDependencies queried |
|
Note
|
getMissingParentStages is used when DAGScheduler submits missing parent ShuffleMapStages (of a stage) and handles JobSubmitted and MapStageSubmitted events.
|
Submitting Missing Tasks of Stage (in a Spark Job) — submitMissingTasks Internal Method
submitMissingTasks(stage: Stage, jobId: Int): UnitsubmitMissingTasks…FIXME
|
Caution
|
FIXME |
When executed, you should see the following DEBUG message in the logs:
DEBUG DAGScheduler: submitMissingTasks([stage])The input stage's pendingPartitions internal field is cleared (it is later filled out with the partitions to run tasks for).
submitMissingTasks requests the stage for missing partitions, i.e. the indices of the partitions to compute.
submitMissingTasks marks the stage as running (i.e. adds it to runningStages internal registry).
submitMissingTasks notifies OutputCommitCoordinator that the stage is started.
|
Note
|
The input maxPartitionId argument handed over to OutputCommitCoordinator depends on the type of the stage, i.e. ShuffleMapStage or ResultStage. ShuffleMapStage tracks the number of partitions itself (as numPartitions property) while ResultStage uses the internal RDD to find out the number.
|
For the missing partitions, submitMissingTasks computes their task locality preferences, i.e. pairs of missing partition ids and their task locality information.
HERE
NOTE: The locality information of a RDD is called preferred locations.
In case of non-fatal exceptions at this time (while getting the locality information), submitMissingTasks creates a new stage attempt.
|
Note
|
A stage attempt is an internal property of a stage. |
Despite the failure to submit any tasks, submitMissingTasks does announce that at least there was an attempt on LiveListenerBus by posting a SparkListenerStageSubmitted message.
|
Note
|
The Spark application’s LiveListenerBus is given when DAGScheduler is created.
|
submitMissingTasks then aborts the stage (with the reason being "Task creation failed" followed by the exception).
The stage is removed from the internal runningStages collection of stages and submitMissingTasks exits.
When no exception was thrown (while computing the locality information for tasks), submitMissingTasks creates a new stage attempt and announces it on LiveListenerBus by posting a SparkListenerStageSubmitted message.
|
Note
|
Yes, that is correct. Whether there was a task submission failure or not, submitMissingTasks creates a new stage attempt and posts a SparkListenerStageSubmitted. That makes sense, doesn’t it?
|
At that time, submitMissingTasks serializes the RDD (of the stage for which tasks are submitted for) and, depending on the type of the stage, the ShuffleDependency (for ShuffleMapStage) or the function (for ResultStage).
|
Note
|
submitMissingTasks uses a closure Serializer that DAGScheduler creates for the entire lifetime when it is created. The closure serializer is available through SparkEnv.
|
The serialized so-called task binary bytes are "wrapped" as a broadcast variable (to make it available for executors to execute later on).
|
Note
|
That exact moment should make clear how important broadcast variables are for Spark itself that you, a Spark developer, can use, too, to distribute data across the nodes in a Spark application in a very efficient way. |
Any NotSerializableException exceptions lead to aborting the stage (with the reason being "Task not serializable: [exception]") and removing the stage from the internal runningStages collection of stages. submitMissingTasks exits.
Any non-fatal exceptions lead to aborting the stage (with the reason being "Task serialization failed" followed by the exception) and removing the stage from the internal runningStages collection of stages. submitMissingTasks exits.
With no exceptions along the way, submitMissingTasks computes a collection of tasks to execute for the missing partitions (of the stage).
submitMissingTasks creates a ShuffleMapTask or ResultTask for every missing partition of the stage being ShuffleMapStage or ResultStage, respectively. submitMissingTasks uses the preferred locations (computed earlier) per partition.
|
Caution
|
FIXME Image with creating tasks for partitions in the stage. |
Any non-fatal exceptions lead to aborting the stage (with the reason being "Task creation failed" followed by the exception) and removing the stage from the internal runningStages collection of stages. submitMissingTasks exits.
If there are tasks to submit for execution (i.e. there are missing partitions in the stage), you should see the following INFO message in the logs:
INFO DAGScheduler: Submitting [size] missing tasks from [stage] ([rdd])submitMissingTasks records the partitions (of the tasks) in the stage's pendingPartitions property.
|
Note
|
pendingPartitions property of the stage was cleared when submitMissingTasks started.
|
You should see the following DEBUG message in the logs:
DEBUG DAGScheduler: New pending partitions: [pendingPartitions]submitMissingTasks submits the tasks to TaskScheduler for execution (with the id of the stage, attempt id, the input jobId, and the properties of the ActiveJob with jobId).
|
Note
|
A TaskScheduler was given when DAGScheduler was created.
|
|
Caution
|
FIXME What are the ActiveJob properties for? Where are they used?
|
submitMissingTasks records the submission time in the stage’s StageInfo and exits.
If however there are no tasks to submit for execution, submitMissingTasks marks the stage as finished (with no errorMessage).
You should see a DEBUG message that varies per the type of the input stage which are:
DEBUG DAGScheduler: Stage [stage] is actually done; (available: [isAvailable],available outputs: [numAvailableOutputs],partitions: [numPartitions])or
DEBUG DAGScheduler: Stage [stage] is actually done; (partitions: [numPartitions])for ShuffleMapStage and ResultStage, respectively.
In the end, with no tasks to submit for execution, submitMissingTasks submits waiting child stages for execution and exits.
|
Note
|
submitMissingTasks is called when DAGScheduler submits a stage for execution.
|
Computing Preferred Locations for Missing Partitions — getPreferredLocs Method
getPreferredLocs(rdd: RDD[_], partition: Int): Seq[TaskLocation]getPreferredLocs is simply an alias for the internal (recursive) getPreferredLocsInternal.
|
Note
|
getPreferredLocs is used when SparkContext gets the locality information for a RDD partition and DAGScheduler submits missing tasks for a stage.
|
Finding BlockManagers (Executors) for Cached RDD Partitions (aka Block Location Discovery) — getCacheLocs Internal Method
getCacheLocs(rdd: RDD[_]): IndexedSeq[Seq[TaskLocation]]getCacheLocs gives TaskLocations (block locations) for the partitions of the input rdd. getCacheLocs caches lookup results in cacheLocs internal registry.
|
Note
|
The size of the collection from getCacheLocs is exactly the number of partitions in rdd RDD.
|
|
Note
|
The size of every TaskLocation collection (i.e. every entry in the result of getCacheLocs) is exactly the number of blocks managed using BlockManagers on executors.
|
Internally, getCacheLocs finds rdd in the cacheLocs internal registry (of partition locations per RDD).
If rdd is not in cacheLocs internal registry, getCacheLocs branches per its storage level.
For NONE storage level (i.e. no caching), the result is an empty locations (i.e. no location preference).
For other non-NONE storage levels, getCacheLocs requests BlockManagerMaster for block locations that are then mapped to TaskLocations with the hostname of the owning BlockManager for a block (of a partition) and the executor id.
|
Note
|
getCacheLocs uses BlockManagerMaster that was defined when DAGScheduler was created.
|
getCacheLocs records the computed block locations per partition (as TaskLocation) in cacheLocs internal registry.
|
Note
|
getCacheLocs requests locations from BlockManagerMaster using RDDBlockId with the RDD id and the partition indices (which implies that the order of the partitions matters to request proper blocks).
|
|
Note
|
DAGScheduler uses TaskLocations (with host and executor) while BlockManagerMaster uses BlockManagerId (to track similar information, i.e. block locations).
|
|
Note
|
getCacheLocs is used when DAGScheduler finds missing parent MapStages and getPreferredLocsInternal.
|
Finding Placement Preferences for RDD Partition (recursively) — getPreferredLocsInternal Internal Method
getPreferredLocsInternal(
rdd: RDD[_],
partition: Int,
visited: HashSet[(RDD[_], Int)]): Seq[TaskLocation]getPreferredLocsInternal first finds the TaskLocations for the partition of the rdd (using cacheLocs internal cache) and returns them.
Otherwise, if not found, getPreferredLocsInternal requests rdd for the preferred locations of partition and returns them.
|
Note
|
Preferred locations of the partitions of a RDD are also called placement preferences or locality preferences. |
Otherwise, if not found, getPreferredLocsInternal finds the first parent NarrowDependency and (recursively) finds TaskLocations.
If all the attempts fail to yield any non-empty result, getPreferredLocsInternal returns an empty collection of TaskLocations.
|
Note
|
getPreferredLocsInternal is used exclusively when DAGScheduler computes preferred locations for missing partitions.
|
Stopping DAGScheduler — stop Method
stop(): Unitstop stops the internal dag-scheduler-message thread pool, dag-scheduler-event-loop, and TaskScheduler.
DAGSchedulerSource Metrics Source
DAGScheduler uses Spark Metrics System (via DAGSchedulerSource) to report metrics about internal status.
|
Caution
|
FIXME What is DAGSchedulerSource?
|
The name of the source is DAGScheduler.
It emits the following numbers:
-
stage.failedStages - the number of failed stages
-
stage.runningStages - the number of running stages
-
stage.waitingStages - the number of waiting stages
-
job.allJobs - the number of all jobs
-
job.activeJobs - the number of active jobs
Updating Accumulators with Partial Values from Completed Tasks — updateAccumulators Internal Method
updateAccumulators(event: CompletionEvent): UnitThe private updateAccumulators method merges the partial values of accumulators from a completed task into their "source" accumulators on the driver.
|
Note
|
It is called by handleTaskCompletion. |
For each AccumulableInfo in the CompletionEvent, a partial value from a task is obtained (from AccumulableInfo.update) and added to the driver’s accumulator (using Accumulable.++= method).
For named accumulators with the update value being a non-zero value, i.e. not Accumulable.zero:
-
stage.latestInfo.accumulablesfor theAccumulableInfo.idis set -
CompletionEvent.taskInfo.accumulableshas a new AccumulableInfo added.
|
Caution
|
FIXME Where are Stage.latestInfo.accumulables and CompletionEvent.taskInfo.accumulables used?
|
Settings
| Spark Property | Default Value | Description |
|---|---|---|
|
When enabled (i.e. |