// HashAggregateExec selected due to:
// sum uses mutable types for aggregate expression
// just a single id column reference of LongType data type
val q = spark.range(10).
groupBy('id % 2 as "group").
agg(sum("id") as "sum")
scala> q.explain
== Physical Plan ==
*HashAggregate(keys=[(id#57L % 2)#69L], functions=[sum(id#57L)])
+- Exchange hashpartitioning((id#57L % 2)#69L, 200)
+- *HashAggregate(keys=[(id#57L % 2) AS (id#57L % 2)#69L], functions=[partial_sum(id#57L)])
+- *Range (0, 10, step=1, splits=8)
scala> println(q.queryExecution.sparkPlan.numberedTreeString)
00 HashAggregate(keys=[(id#57L % 2)#72L], functions=[sum(id#57L)], output=[group#60L, sum#64L])
01 +- HashAggregate(keys=[(id#57L % 2) AS (id#57L % 2)#72L], functions=[partial_sum(id#57L)], output=[(id#57L % 2)#72L, sum#74L])
02 +- Range (0, 10, step=1, splits=8)
// Going low level...watch your steps :)
import q.queryExecution.optimizedPlan
import org.apache.spark.sql.catalyst.plans.logical.Aggregate
val aggLog = optimizedPlan.asInstanceOf[Aggregate]
import org.apache.spark.sql.catalyst.planning.PhysicalAggregation
import org.apache.spark.sql.catalyst.expressions.aggregate.AggregateExpression
val aggregateExpressions: Seq[AggregateExpression] = PhysicalAggregation.unapply(aggLog).get._2
val aggregateBufferAttributes = aggregateExpressions.
flatMap(_.aggregateFunction.aggBufferAttributes)
import org.apache.spark.sql.execution.aggregate.HashAggregateExec
// that's the exact reason why HashAggregateExec was selected
// Aggregation execution planning strategy prefers HashAggregateExec
scala> val useHash = HashAggregateExec.supportsAggregate(aggregateBufferAttributes)
useHash: Boolean = true
val execPlan = q.queryExecution.sparkPlan
val hashAggExec = execPlan.asInstanceOf[HashAggregateExec]
scala> println(execPlan.numberedTreeString)
00 HashAggregate(keys=[(id#39L % 2)#50L], functions=[sum(id#39L)], output=[group#42L, sum#46L])
01 +- HashAggregate(keys=[(id#39L % 2) AS (id#39L % 2)#50L], functions=[partial_sum(id#39L)], output=[(id#39L % 2)#50L, sum#52L])
02 +- Range (0, 10, step=1, splits=8)
val hashAggExecRDD = hashAggExec.execute // <-- calls doExecute
scala> println(hashAggExecRDD.toDebugString)
(8) MapPartitionsRDD[14] at execute at <console>:35 []
| MapPartitionsRDD[13] at execute at <console>:35 []
| MapPartitionsRDD[12] at execute at <console>:35 []
| ParallelCollectionRDD[11] at execute at <console>:35 []HashAggregateExec Aggregate Physical Operator for Hash-Based Aggregation
HashAggregateExec is a unary physical operator for hash-based aggregation that is created (indirectly through AggUtils.createAggregate) when:
-
Aggregation execution planning strategy selects the aggregate physical operator for an Aggregate logical operator
-
Structured Streaming’s
StatefulAggregationStrategystrategy creates plan for streamingEventTimeWatermarkor Aggregate logical operators
|
Note
|
HashAggregateExec is the preferred aggregate physical operator for Aggregation execution planning strategy (over ObjectHashAggregateExec and SortAggregateExec).
|
HashAggregateExec supports code generation (aka codegen).
| Name | Description |
|---|---|
|
aggregate time |
|
number of output rows |
|
peak memory |
|
spill size |
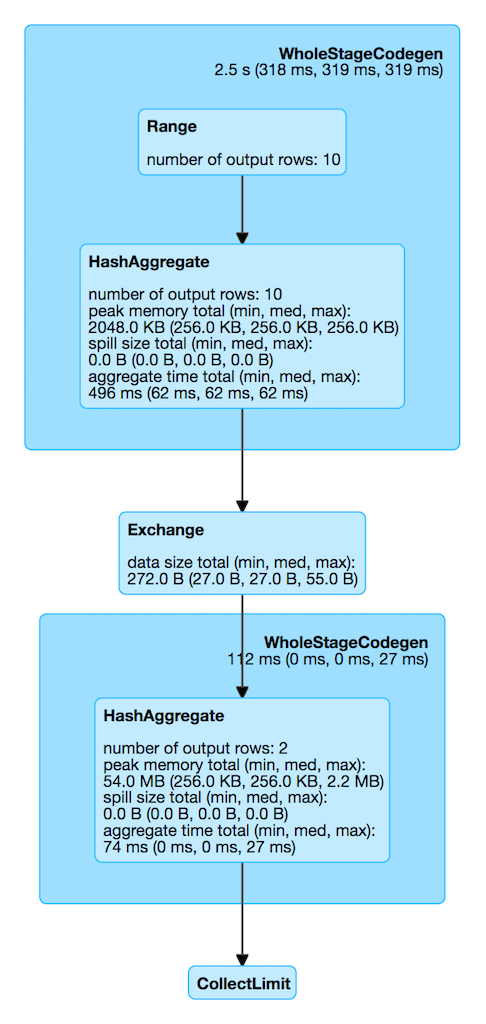
Figure 1. HashAggregateExec in web UI (Details for Query)
| Name | Description |
|---|---|
Collection of |
|
Output schema for the input NamedExpressions |
requiredChildDistribution varies per the input required child distribution expressions.
| requiredChildDistributionExpressions | Distribution |
|---|---|
Defined, but empty |
|
Non-empty |
|
Undefined ( |
|
|
Note
|
(No distinct in aggregation)
(one distinct in aggregation)
FIXME for the following two cases in aggregation with one distinct. |
|
Note
|
The prefix for variable names for HashAggregateExec operators in CodegenSupport-generated code is agg.
|
testFallbackStartsAt Internal Value
|
Caution
|
FIXME |
supportsAggregate Method
supportsAggregate(aggregateBufferAttributes: Seq[Attribute]): BooleansupportsAggregate first builds the schema of the aggregation buffer (from the input aggregateBufferAttributes attributes) and checks if UnsafeFixedWidthAggregationMap supports it (i.e. the schema uses mutable field data types only that have fixed length and can be mutated in place in an UnsafeRow).
|
Note
|
supportsAggregate is used exclusively when AggUtils.createAggregate selects an aggregate physical operator given aggregate expressions.
|
Creating HashAggregateExec Instance
HashAggregateExec takes the following when created:
-
Required child distribution expressions
-
Grouping named expressions
-
Aggregate attributes
-
Output named expressions
-
Child physical operator
Executing HashAggregateExec — doExecute Method
doExecute(): RDD[InternalRow]doExecute executes the input child SparkPlan (to produce InternalRow objects) and applies calculation over partitions (using RDD.mapPartitions).
|
Important
|
RDD.mapPartitions does not preserve partitioning and neither does HashAggregateExec when executed.
|
In the mapPartitions block, doExecute creates one of the following:
-
an empty iterator for no-record partitions with at least one grouping expression
|
Note
|
doExecute is a part of SparkPlan Contract to produce the result of a structured query as an RDD of InternalRow objects.
|
doProduce Method
doProduce(ctx: CodegenContext): StringdoProduce executes doProduceWithoutKeys when no groupingExpressions were specified for the HashAggregateExec or doProduceWithKeys otherwise.
|
Note
|
doProduce is a part of CodegenSupport Contract.
|