Task
Task (aka command) is the smallest individual unit of execution that is launched to compute a RDD partition.
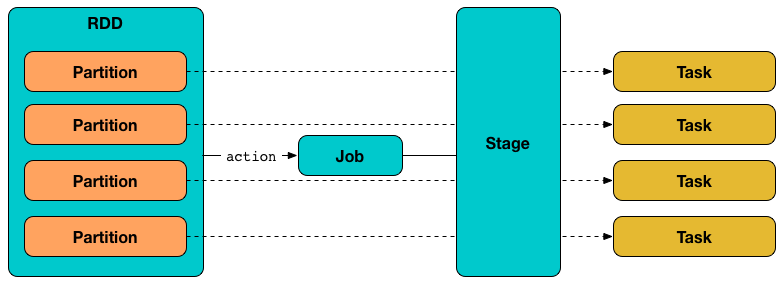
Figure 1. Tasks correspond to partitions in RDD
A task is described by the Task contract with a single runTask to run it and optional placement preferences to place the computation on right executors.
There are two concrete implementations of Task contract:
-
ShuffleMapTask that executes a task and divides the task’s output to multiple buckets (based on the task’s partitioner).
-
ResultTask that executes a task and sends the task’s output back to the driver application.
The very last stage in a Spark job consists of multiple ResultTasks, while earlier stages can only be ShuffleMapTasks.
|
Caution
|
FIXME You could have a Spark job with ShuffleMapTask being the last. |
Tasks are launched on executors and ran when TaskRunner starts.
In other (more technical) words, a task is a computation on the records in a RDD partition in a stage of a RDD in a Spark job.
|
Note
|
T is the type defined when a Task is created.
|
| Name | Description |
|---|---|
Used when ??? |
|
Set for a |
|
Used when ??? |
|
Used when ??? |
|
Used when ??? |
|
Created lazily when Used when ??? |
|
TaskMemoryManager that manages the memory allocated by the task. Used when ??? |
|
Used when ??? |
A task can only belong to one stage and operate on a single partition. All tasks in a stage must be completed before the stages that follow can start.
Tasks are spawned one by one for each stage and partition.
|
Caution
|
FIXME What are stageAttemptId and taskAttemptId?
|
Task Contract
def runTask(context: TaskContext): T
def preferredLocations: Seq[TaskLocation] = Nil|
Note
|
Task is a private[spark] contract.
|
| Method | Description |
|---|---|
Used when a task runs. |
|
Collection of TaskLocations. Used exclusively when Empty by default and so no task location preferences are defined that says the task could be launched on any executor. Defined by the custom tasks, i.e. ShuffleMapTask and ResultTask. |
Creating Task Instance
Task takes the following when created:
-
Stage ID
-
Partition ID
-
Serialized TaskMetrics (that were part of the owning Stage)
-
(optional) Job ID
Task initializes the internal registries and counters.
Running Task Thread — run Method
run(
taskAttemptId: Long,
attemptNumber: Int,
metricsSystem: MetricsSystem): T|
Note
|
run uses SparkEnv to access the current BlockManager.
|
run creates a TaskContextImpl that in turn becomes the task’s TaskContext.
|
Note
|
run is a final method and so must not be overriden.
|
run checks _killed flag and, if enabled, kills the task (with interruptThread flag disabled).
run creates a Hadoop CallerContext and sets it.
run runs the task.
|
Note
|
This is the moment when the custom Task's runTask is executed.
|
In the end, run notifies TaskContextImpl that the task has completed (regardless of the final outcome — a success or a failure).
In case of any exceptions, run notifies TaskContextImpl that the task has failed. run requests MemoryStore to release unroll memory for this task (for both ON_HEAP and OFF_HEAP memory modes).
|
Note
|
run uses SparkEnv to access the current BlockManager that it uses to access MemoryStore.
|
|
Note
|
run uses SparkEnv to access the current MemoryManager.
|
|
Note
|
run is used exclusively when TaskRunner starts. The Task instance has just been deserialized from taskBytes that were sent over the wire to an executor. localProperties and TaskMemoryManager are already assigned.
|
Task States
A task can be in one of the following states (as described by TaskState enumeration):
-
LAUNCHING -
RUNNINGwhen the task is being started. -
FINISHEDwhen the task finished with the serialized result. -
FAILEDwhen the task fails, e.g. when FetchFailedException,CommitDeniedExceptionor anyThrowableoccurs -
KILLEDwhen an executor kills a task. -
LOST
States are the values of org.apache.spark.TaskState.
|
Note
|
Task status updates are sent from executors to the driver through ExecutorBackend. |
Task is finished when it is in one of FINISHED, FAILED, KILLED, LOST.
LOST and FAILED states are considered failures.
|
Tip
|
Task states correspond to org.apache.mesos.Protos.TaskState. |
Collect Latest Values of (Internal and External) Accumulators — collectAccumulatorUpdates Method
collectAccumulatorUpdates(taskFailed: Boolean = false): Seq[AccumulableInfo]collectAccumulatorUpdates collects the latest values of internal and external accumulators from a task (and returns the values as a collection of AccumulableInfo).
Internally, collectAccumulatorUpdates takes TaskMetrics.
|
Note
|
collectAccumulatorUpdates uses TaskContextImpl to access the task’s TaskMetrics.
|
collectAccumulatorUpdates collects the latest values of:
-
internal accumulators whose current value is not the zero value and the
RESULT_SIZEaccumulator (regardless whether the value is its zero or not). -
external accumulators when
taskFailedis disabled (false) or which should be included on failures.
collectAccumulatorUpdates returns an empty collection when TaskContextImpl is not initialized.
|
Note
|
collectAccumulatorUpdates is used when TaskRunner runs a task (and sends a task’s final results back to the driver).
|
Killing Task — kill Method
kill(interruptThread: Boolean)kill marks the task to be killed, i.e. it sets the internal _killed flag to true.
kill calls TaskContextImpl.markInterrupted when context is set.
If interruptThread is enabled and the internal taskThread is available, kill interrupts it.
|
Caution
|
FIXME When could context and interruptThread not be set?
|