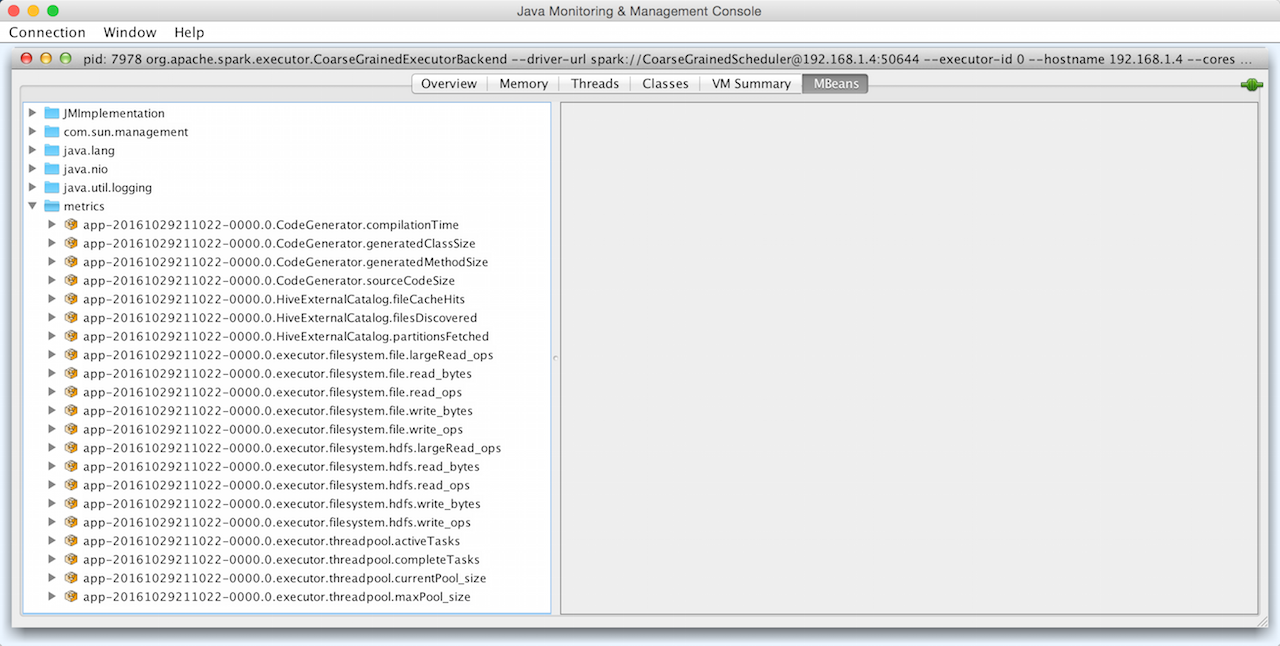
ExecutorSource
ExecutorSource is a Source of metrics for an Executor. It uses an executor’s threadPool for calculating the gauges.
|
Note
|
Every executor has its own separate ExecutorSource that is registered when CoarseGrainedExecutorBackend receives a RegisteredExecutor.
|
The name of a ExecutorSource is executor.
Figure 1. ExecutorSource in JConsole (using Spark Standalone)
| Gauge | Description |
|---|---|
threadpool.activeTasks |
Approximate number of threads that are actively executing tasks. |
threadpool.completeTasks |
Approximate total number of tasks that have completed execution. |
threadpool.currentPool_size |
Current number of threads in the pool. |
threadpool.maxPool_size |
Maximum allowed number of threads that have ever simultaneously been in the pool |
filesystem.hdfs.read_bytes |
Uses Hadoop’s FileSystem.getAllStatistics() and |
filesystem.hdfs.write_bytes |
Uses Hadoop’s FileSystem.getAllStatistics() and |
filesystem.hdfs.read_ops |
Uses Hadoop’s FileSystem.getAllStatistics() and |
filesystem.hdfs.largeRead_ops |
Uses Hadoop’s FileSystem.getAllStatistics() and |
filesystem.hdfs.write_ops |
Uses Hadoop’s FileSystem.getAllStatistics() and |
filesystem.file.read_bytes |
The same as |
filesystem.file.write_bytes |
The same as |
filesystem.file.read_ops |
The same as |
filesystem.file.largeRead_ops |
The same as |
filesystem.file.write_ops |
The same as |