Thrift JDBC/ODBC Server — Spark Thrift Server (STS)
Thrift JDBC/ODBC Server (aka Spark Thrift Server or STS) is Spark SQL’s port of Apache Hive’s HiveServer2 that allows JDBC/ODBC clients to execute SQL queries over JDBC and ODBC protocols on Apache Spark.
With Spark Thrift Server, business users can work with their shiny Business Intelligence (BI) tools, e.g. Tableau or Microsoft Excel, and connect to Apache Spark using the ODBC interface. That brings the in-memory distributed capabilities of Spark SQL’s query engine (with all the Catalyst query optimizations you surely like very much) to environments that were initially "disconnected".
Beside, SQL queries in Spark Thrift Server share the same SparkContext that helps further improve performance of SQL queries using the same data sources.
Spark Thrift Server is a Spark standalone application that you start using start-thriftserver.sh and stop using stop-thriftserver.sh shell scripts.
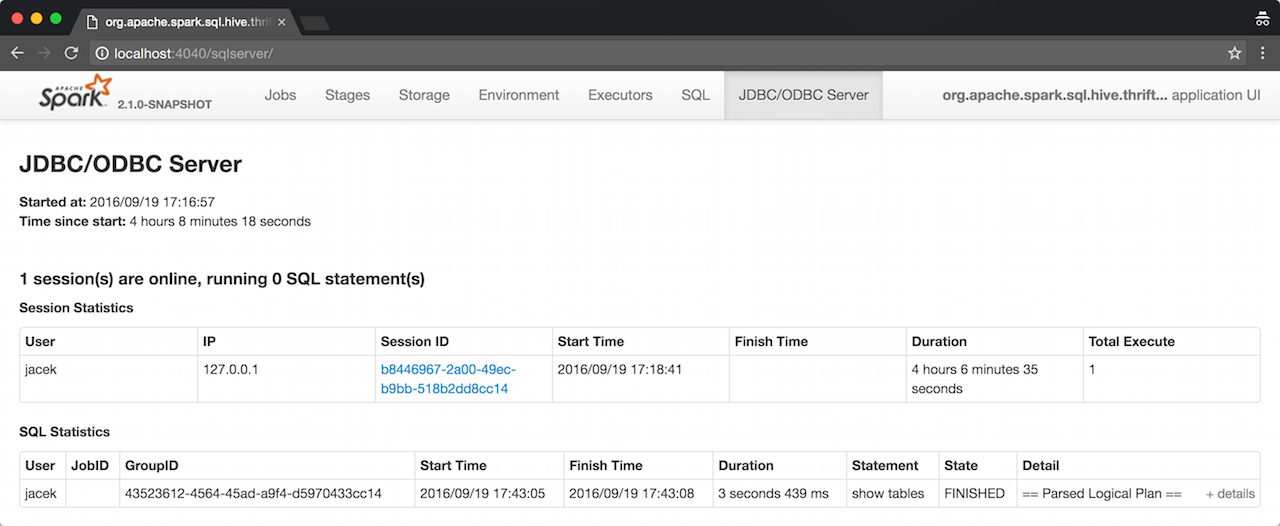
Spark Thrift Server has its own tab in web UI — JDBC/ODBC Server available at /sqlserver URL.
Figure 1. Spark Thrift Server’s web UI
Spark Thrift Server can work in HTTP or binary transport modes.
Use beeline command-line tool or SQuirreL SQL Client or Spark SQL’s DataSource API to connect to Spark Thrift Server through the JDBC interface.
Spark Thrift Server extends spark-submit's command-line options with --hiveconf [prop=value].
|
Important
|
You have to enable Refer to Building Apache Spark from Sources. |
|
Tip
|
Enable Add the following line to Refer to Logging. |
Starting Thrift JDBC/ODBC Server — start-thriftserver.sh
You can start Thrift JDBC/ODBC Server using ./sbin/start-thriftserver.sh shell script.
With INFO logging level enabled, when you execute the script you should see the following INFO messages in the logs:
INFO HiveThriftServer2: Started daemon with process name: 16633@japila.local
INFO HiveThriftServer2: Starting SparkContext
...
INFO HiveThriftServer2: HiveThriftServer2 startedInternally, start-thriftserver.sh script submits org.apache.spark.sql.hive.thriftserver.HiveThriftServer2 standalone application for execution (using spark-submit).
$ ./bin/spark-submit --class org.apache.spark.sql.hive.thriftserver.HiveThriftServer2|
Tip
|
Using the more explicit approach with spark-submit to start Spark Thrift Server could be easier to trace execution by seeing the logs printed out to the standard output and hence terminal directly.
|
Using Beeline JDBC Client to Connect to Spark Thrift Server
beeline is a command-line tool that allows you to access Spark Thrift Server using the JDBC interface on command line. It is included in the Spark distribution in bin directory.
$ ./bin/beeline
Beeline version 1.2.1.spark2 by Apache Hive
beeline>You can connect to Spark Thrift Server using connect command as follows:
beeline> !connect jdbc:hive2://localhost:10000When connecting in non-secure mode, simply enter the username on your machine and a blank password.
beeline> !connect jdbc:hive2://localhost:10000
Connecting to jdbc:hive2://localhost:10000
Enter username for jdbc:hive2://localhost:10000: jacek
Enter password for jdbc:hive2://localhost:10000: [press ENTER]
Connected to: Spark SQL (version 2.1.0-SNAPSHOT)
Driver: Hive JDBC (version 1.2.1.spark2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://localhost:10000>Once connected, you can send SQL queries (as if Spark SQL were a JDBC-compliant database).
0: jdbc:hive2://localhost:10000> show databases;
+---------------+--+
| databaseName |
+---------------+--+
| default |
+---------------+--+
1 row selected (0.074 seconds)Connecting to Spark Thrift Server using SQuirreL SQL Client 3.7.1
Spark Thrift Server allows for remote access to Spark SQL using JDBC protocol.
|
Note
|
This section was tested with SQuirreL SQL Client 3.7.1 (squirrelsql-3.7.1-standard.zip) on Mac OS X.
|
SQuirreL SQL Client is a Java SQL client for JDBC-compliant databases.
Run the client using java -jar squirrel-sql.jar.
Figure 2. SQuirreL SQL Client
You first have to configure a JDBC driver for Spark Thrift Server. Spark Thrift Server uses org.spark-project.hive:hive-jdbc:1.2.1.spark2 dependency that is the JDBC driver (that also downloads transitive dependencies).
|
Tip
|
The Hive JDBC Driver, i.e. hive-jdbc-1.2.1.spark2.jar and other jar files are in jars directory of the Apache Spark distribution (or assembly/target/scala-2.11/jars for local builds).
|
| Parameter | Description |
|---|---|
Name |
Spark Thrift Server |
Example URL |
|
Extra Class Path |
All the jar files of your Spark distribution |
Class Name |
|
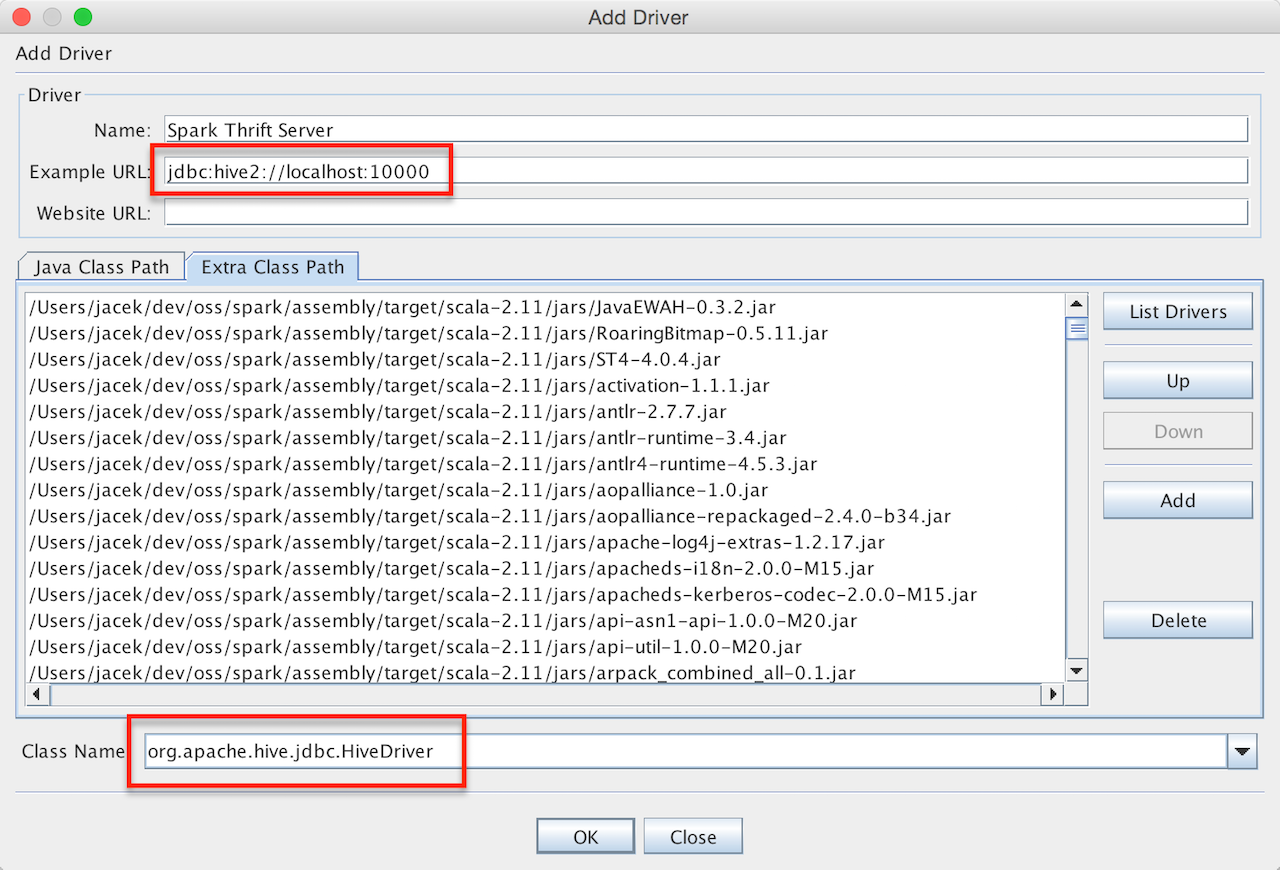
Figure 3. Adding Hive JDBC Driver in SQuirreL SQL Client
With the Hive JDBC Driver defined, you can connect to Spark SQL Thrift Server.
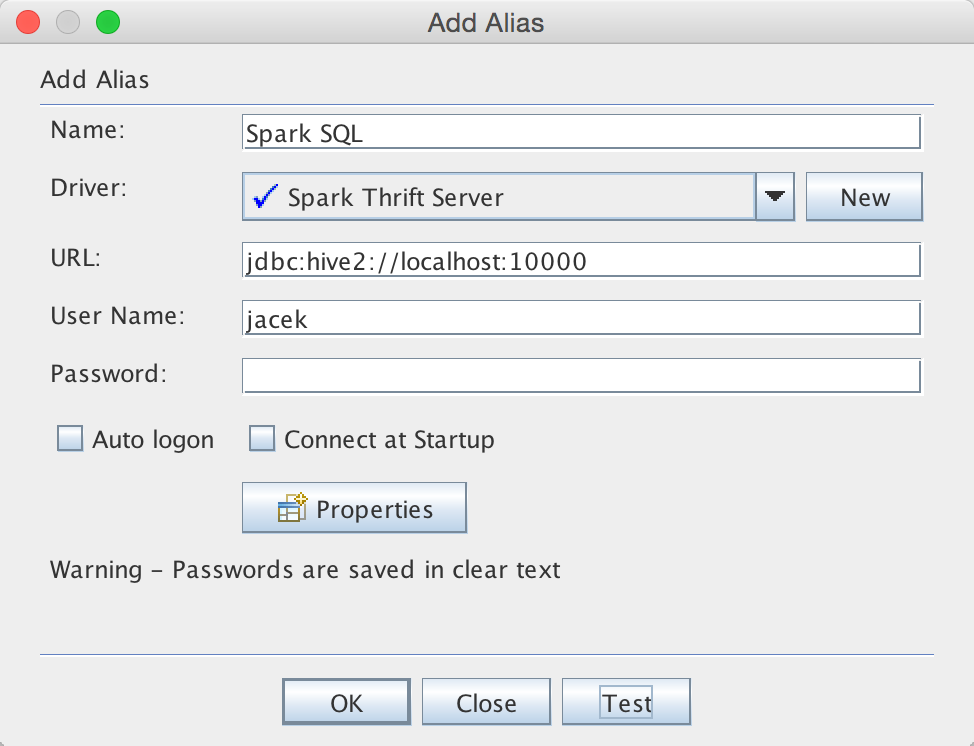
Figure 4. Adding Hive JDBC Driver in SQuirreL SQL Client
Since you did not specify the database to use, Spark SQL’s default is used.
Figure 5. SQuirreL SQL Client Connected to Spark Thrift Server (Metadata Tab)
Below is show tables SQL query in SQuirrel SQL Client executed in Spark SQL through Spark Thrift Server.
Figure 6.
show tables SQL Query in SQuirrel SQL Client using Spark Thrift ServerUsing Spark SQL’s DataSource API to Connect to Spark Thrift Server
What might seem a quite artificial setup at first is accessing Spark Thrift Server using Spark SQL’s DataSource API, i.e. DataFrameReader's jdbc method.
|
Tip
|
When executed in Use spark.sql.warehouse.dir to point to another directory for You should also not share the same home directory between them since |
// Inside spark-shell
// Paste in :paste mode
val df = spark
.read
.option("url", "jdbc:hive2://localhost:10000") (1)
.option("dbtable", "people") (2)
.format("jdbc")
.load-
Connect to Spark Thrift Server at localhost on port 10000
-
Use
peopletable. It assumes thatpeopletable is available.
ThriftServerTab — web UI’s Tab for Spark Thrift Server
ThriftServerTab is…FIXME
|
Caution
|
FIXME Elaborate |
Stopping Thrift JDBC/ODBC Server — stop-thriftserver.sh
You can stop a running instance of Thrift JDBC/ODBC Server using ./sbin/stop-thriftserver.sh shell script.
With DEBUG logging level enabled, you should see the following messages in the logs:
ERROR HiveThriftServer2: RECEIVED SIGNAL TERM
DEBUG SparkSQLEnv: Shutting down Spark SQL Environment
INFO HiveServer2: Shutting down HiveServer2
INFO BlockManager: BlockManager stopped
INFO SparkContext: Successfully stopped SparkContext|
Tip
|
You can also send SIGTERM signal to the process of Thrift JDBC/ODBC Server, i.e. kill [PID] that triggers the same sequence of shutdown steps as stop-thriftserver.sh.
|
Transport Mode
Spark Thrift Server can be configured to listen in two modes (aka transport modes):
-
Binary mode — clients should send thrift requests in binary
-
HTTP mode — clients send thrift requests over HTTP.
You can control the transport modes using
HIVE_SERVER2_TRANSPORT_MODE=http or hive.server2.transport.mode (default: binary). It can be binary (default) or http.
HiveThriftServer2Listener
|
Caution
|
FIXME |