IndexShuffleBlockResolver
IndexShuffleBlockResolver is the one and only ShuffleBlockResolver in Spark.
IndexShuffleBlockResolver manages shuffle block data and uses shuffle index files for faster shuffle data access. IndexShuffleBlockResolver can write a shuffle block index and data file, find and remove shuffle index and data files per shuffle and
map.
|
Note
|
Shuffle block data files are more often referred as map outputs files. |
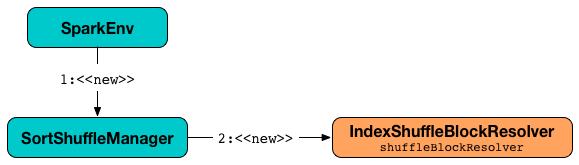
IndexShuffleBlockResolver is managed exclusively by SortShuffleManager (so BlockManager can access shuffle block data).
Figure 1. SortShuffleManager creates IndexShuffleBlockResolver
IndexShuffleBlockResolver is later passed in when SortShuffleManager creates a ShuffleWriter for ShuffleHandle.
| Name | Initial Value | Description |
|---|---|---|
|
TransportConf for |
Used when |
Creating IndexShuffleBlockResolver Instance
IndexShuffleBlockResolver takes the following when created:
-
BlockManager (default: unspecified and
SparkEnvis used to access one)
IndexShuffleBlockResolver initializes the internal properties.
|
Note
|
IndexShuffleBlockResolver is created exclusively when SortShuffleManager is created.
|
Writing Shuffle Index and Data Files — writeIndexFileAndCommit Method
writeIndexFileAndCommit(
shuffleId: Int,
mapId: Int,
lengths: Array[Long],
dataTmp: File): UnitInternally, writeIndexFileAndCommit first finds the index file for the input shuffleId and mapId.
writeIndexFileAndCommit creates a temporary file for the index file (in the same directory) and writes offsets (as the moving sum of the input lengths starting from 0 to the final offset at the end for the end of the output file).
|
Note
|
The offsets are the sizes in the input lengths exactly.
|
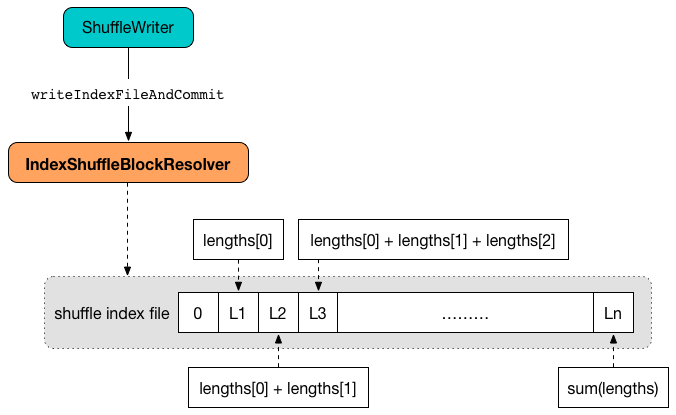
Figure 2. writeIndexFileAndCommit and offsets in a shuffle index file
writeIndexFileAndCommit requests a shuffle block data file for the input shuffleId and mapId.
writeIndexFileAndCommit checks if the given index and data files match each other (aka consistency check).
If the consistency check fails, it means that another attempt for the same task has already written the map outputs successfully and so the input dataTmp and temporary index files are deleted (as no longer correct).
If the consistency check succeeds, the existing index and data files are deleted (if they exist) and the temporary index and data files become "official", i.e. renamed to their final names.
In case of any IO-related exception, writeIndexFileAndCommit throws a IOException with the messages:
fail to rename file [indexTmp] to [indexFile]or
fail to rename file [dataTmp] to [dataFile]|
Note
|
writeIndexFileAndCommit is used when ShuffleWriter is requested to write records to shuffle system, i.e. SortShuffleWriter, BypassMergeSortShuffleWriter, and UnsafeShuffleWriter.
|
Creating ManagedBuffer to Read Shuffle Block Data File — getBlockData Method
getBlockData(blockId: ShuffleBlockId): ManagedBuffer|
Note
|
getBlockData is a part of ShuffleBlockResolver contract.
|
Internally, getBlockData finds the index file for the input shuffle blockId.
|
Note
|
ShuffleBlockId knows shuffleId and mapId.
|
getBlockData discards blockId.reduceId bytes of data from the index file.
|
Note
|
getBlockData uses Guava’s com.google.common.io.ByteStreams to skip the bytes.
|
getBlockData reads the start and end offsets from the index file and then creates a FileSegmentManagedBuffer to read the data file for the offsets (using transportConf internal property).
|
Note
|
The start and end offsets are the offset and the length of the file segment for the block data. |
In the end, getBlockData closes the index file.
Checking Consistency of Shuffle Index and Data Files and Returning Block Lengths — checkIndexAndDataFile Internal Method
checkIndexAndDataFile(index: File, data: File, blocks: Int): Array[Long]checkIndexAndDataFile first checks if the size of the input index file is exactly the input blocks multiplied by 8.
checkIndexAndDataFile returns null when the numbers, and hence the shuffle index and data files, don’t match.
checkIndexAndDataFile reads the shuffle index file and converts the offsets into lengths of each block.
checkIndexAndDataFile makes sure that the size of the input shuffle data file is exactly the sum of the block lengths.
checkIndexAndDataFile returns the block lengths if the numbers match, and null otherwise.
|
Note
|
checkIndexAndDataFile is used exclusively when IndexShuffleBlockResolver writes shuffle index and data files.
|
Requesting Shuffle Block Index File (from DiskBlockManager) — getIndexFile Internal Method
getIndexFile(shuffleId: Int, mapId: Int): FilegetIndexFile requests BlockManager for the current DiskBlockManager.
|
Note
|
getIndexFile uses SparkEnv to access the current BlockManager unless specified when IndexShuffleBlockResolver is created.
|
getIndexFile then requests DiskBlockManager for the shuffle index file given the input shuffleId and mapId (as ShuffleIndexBlockId)
|
Note
|
getIndexFile is used when IndexShuffleBlockResolver writes shuffle index and data files, creates a ManagedBuffer to read a shuffle block data file, and ultimately removes the shuffle index and data files.
|
Requesting Shuffle Block Data File — getDataFile Method
getDataFile(shuffleId: Int, mapId: Int): File|
Note
|
getDataFile uses SparkEnv to access the current BlockManager unless specified when IndexShuffleBlockResolver is created.
|
getDataFile then requests DiskBlockManager for the shuffle block data file given the input shuffleId, mapId, and the special reduce id 0 (as ShuffleDataBlockId).
|
Note
|
|
Removing Shuffle Index and Data Files (For Single Map) — removeDataByMap Method
removeDataByMap(shuffleId: Int, mapId: Int): UnitremoveDataByMap finds and deletes the shuffle data for the input shuffleId and mapId first followed by finding and deleting the shuffle data index file.
When removeDataByMap fails deleting the files, you should see a WARN message in the logs.
WARN Error deleting data [path]or
WARN Error deleting index [path]|
Note
|
removeDataByMap is used exclusively when SortShuffleManager unregisters a shuffle, i.e. removes a shuffle from a shuffle system.
|
Stopping IndexShuffleBlockResolver — stop Method
stop(): Unit|
Note
|
stop is a part of ShuffleBlockResolver contract.
|
stop is a noop operation, i.e. does nothing when called.