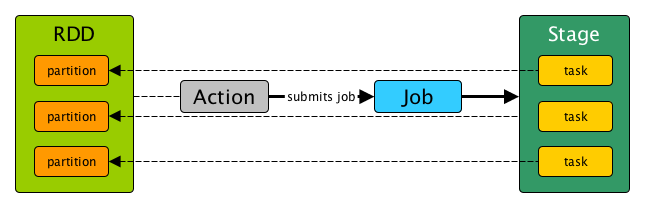
Stage — Physical Unit Of Execution
A stage is a physical unit of execution. It is a step in a physical execution plan.
A stage is a set of parallel tasks — one task per partition (of an RDD that computes partial results of a function executed as part of a Spark job).
Figure 1. Stage, tasks and submitting a job
In other words, a Spark job is a computation with that computation sliced into stages.
A stage is uniquely identified by id. When a stage is created, DAGScheduler increments internal counter nextStageId to track the number of stage submissions.
A stage can only work on the partitions of a single RDD (identified by rdd), but can be associated with many other dependent parent stages (via internal field parents), with the boundary of a stage marked by shuffle dependencies.
Submitting a stage can therefore trigger execution of a series of dependent parent stages (refer to RDDs, Job Execution, Stages, and Partitions).

Figure 2. Submitting a job triggers execution of the stage and its parent stages
Finally, every stage has a firstJobId that is the id of the job that submitted the stage.
There are two types of stages:
-
ShuffleMapStage is an intermediate stage (in the execution DAG) that produces data for other stage(s). It writes map output files for a shuffle. It can also be the final stage in a job in Adaptive Query Planning / Adaptive Scheduling.
-
ResultStage is the final stage that executes a Spark action in a user program by running a function on an RDD.
When a job is submitted, a new stage is created with the parent ShuffleMapStage linked — they can be created from scratch or linked to, i.e. shared, if other jobs use them already.
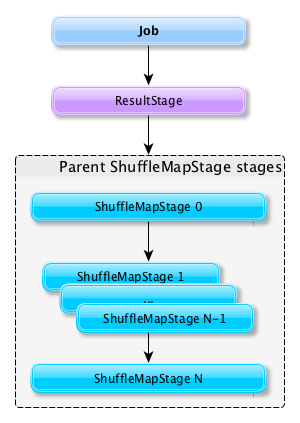
Figure 3. DAGScheduler and Stages for a job
A stage tracks the jobs (their ids) it belongs to (using the internal jobIds registry).
DAGScheduler splits up a job into a collection of stages. Each stage contains a sequence of narrow transformations that can be completed without shuffling the entire data set, separated at shuffle boundaries, i.e. where shuffle occurs. Stages are thus a result of breaking the RDD graph at shuffle boundaries.
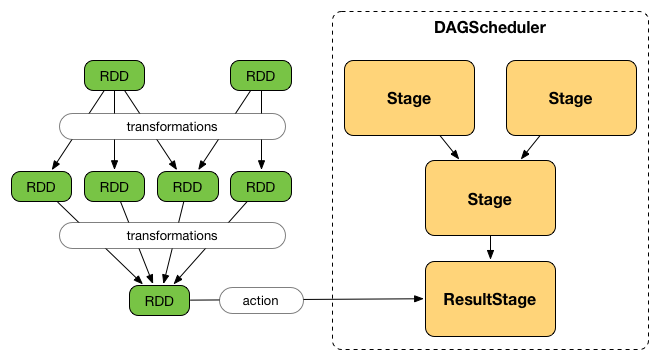
Figure 4. Graph of Stages
Shuffle boundaries introduce a barrier where stages/tasks must wait for the previous stage to finish before they fetch map outputs.
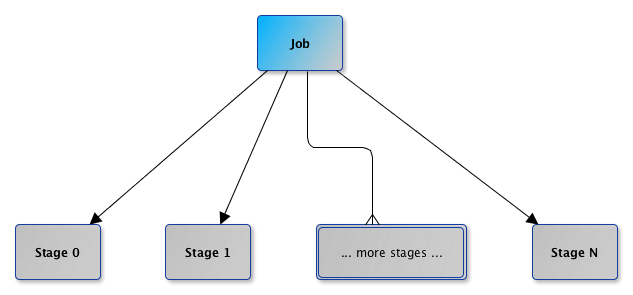
Figure 5. DAGScheduler splits a job into stages
RDD operations with narrow dependencies, like map() and filter(), are pipelined together into one set of tasks in each stage, but operations with shuffle dependencies require multiple stages, i.e. one to write a set of map output files, and another to read those files after a barrier.
In the end, every stage will have only shuffle dependencies on other stages, and may compute multiple operations inside it. The actual pipelining of these operations happens in the RDD.compute() functions of various RDDs, e.g. MappedRDD, FilteredRDD, etc.
At some point of time in a stage’s life, every partition of the stage gets transformed into a task - ShuffleMapTask or ResultTask for ShuffleMapStage and ResultStage, respectively.
Partitions are computed in jobs, and result stages may not always need to compute all partitions in their target RDD, e.g. for actions like first() and lookup().
DAGScheduler prints the following INFO message when there are tasks to submit:
INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 36 (ShuffledRDD[86] at reduceByKey at <console>:24)There is also the following DEBUG message with pending partitions:
DEBUG DAGScheduler: New pending partitions: Set(0)Tasks are later submitted to Task Scheduler (via taskScheduler.submitTasks).
When no tasks in a stage can be submitted, the following DEBUG message shows in the logs:
FIXME| Name | Description |
|---|---|
Long description of the stage Used when…FIXME |
|
Used when…FIXME |
|
Set of jobs the stage belongs to. Used when…FIXME |
|
Name of the stage Used when…FIXME |
|
The ID for the next attempt of the stage. Used when…FIXME |
|
Number of partitions Used when…FIXME |
|
Set of pending partitions Used when…FIXME |
|
Internal cache with…FIXME Used when…FIXME |
Stage Contract
abstract class Stage {
def findMissingPartitions(): Seq[Int]
}|
Note
|
Stage is a private[scheduler] abstract contract.
|
| Method | Description |
|---|---|
Used when… |
findMissingPartitions Method
Stage.findMissingPartitions() calculates the ids of the missing partitions, i.e. partitions for which the ActiveJob knows they are not finished (and so they are missing).
A ResultStage stage knows it by querying the active job about partition ids (numPartitions) that are not finished (using ActiveJob.finished array of booleans).
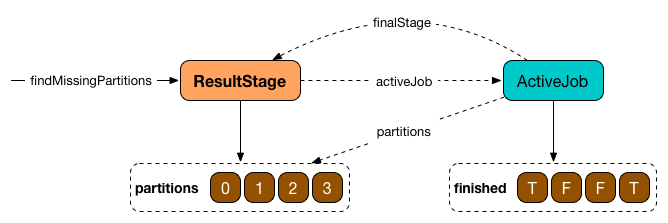
Figure 6. ResultStage.findMissingPartitions and ActiveJob
In the above figure, partitions 1 and 2 are not finished (F is false while T is true).
failedOnFetchAndShouldAbort Method
Stage.failedOnFetchAndShouldAbort(stageAttemptId: Int): Boolean checks whether the number of fetch failed attempts (using fetchFailedAttemptIds) exceeds the number of consecutive failures allowed for a given stage (that should then be aborted)
|
Note
|
The number of consecutive failures for a stage is not configurable. |
Getting StageInfo For Most Recent Attempt — latestInfo Method
latestInfo: StageInfolatestInfo simply returns the most recent StageInfo (i.e. makes it accessible).
Creating New Stage Attempt (as StageInfo) — makeNewStageAttempt Method
makeNewStageAttempt(
numPartitionsToCompute: Int,
taskLocalityPreferences: Seq[Seq[TaskLocation]] = Seq.empty): UnitmakeNewStageAttempt creates a new TaskMetrics and registers the internal accumulators (using the RDD’s SparkContext).
|
Note
|
makeNewStageAttempt uses rdd that was defined when Stage was created.
|
makeNewStageAttempt sets _latestInfo to be a StageInfo from the current stage (with nextAttemptId, numPartitionsToCompute, and taskLocalityPreferences).
makeNewStageAttempt increments nextAttemptId counter.
|
Note
|
makeNewStageAttempt is used exclusively when DAGScheduler submits missing tasks for a stage.
|