spark.rpc.message.maxSize should not be greater than 2047 MBCoarseGrainedSchedulerBackend
CoarseGrainedSchedulerBackend is a SchedulerBackend.
CoarseGrainedSchedulerBackend is an ExecutorAllocationClient.
CoarseGrainedSchedulerBackend is responsible for requesting resources from a cluster manager for executors that it in turn uses to launch tasks (on coarse-grained executors).
CoarseGrainedSchedulerBackend holds executors for the duration of the Spark job rather than relinquishing executors whenever a task is done and asking the scheduler to launch a new executor for each new task.
|
Caution
|
FIXME Picture with dependencies |
CoarseGrainedSchedulerBackend registers CoarseGrainedScheduler RPC Endpoint that executors use for RPC communication.
|
Note
|
Active executors are executors that are not pending to be removed or lost. |
| Cluster Environment | CoarseGrainedSchedulerBackend |
|---|---|
Spark Standalone |
|
Spark on YARN |
|
Spark on Mesos |
|
Note
|
CoarseGrainedSchedulerBackend is only created indirectly through built-in implementations per cluster environment.
|
| Name | Initial Value | Description |
|---|---|---|
The last (highest) identifier of all allocated executors. Used exclusively in |
||
Current time |
||
spark.rpc.askTimeout or spark.network.timeout or |
Default timeout for blocking RPC messages (aka ask messages). |
|
(uninitialized) |
RPC endpoint reference to Initialized when Used when |
|
empty |
Registry of NOTE: Element added when |
|
empty |
Executors marked as removed but the confirmation from a cluster manager has not arrived yet. |
|
empty |
Registry of hostnames and possible number of task running on them. |
|
|
Number of pending tasks…FIXME |
|
spark.rpc.message.maxSize but not greater than |
Maximum RPC message size in MB. When above |
|
|
||
|
Total number of CPU cores, i.e. the sum of all the cores on all executors. |
|
|
Total number of registered executors |
|
Tip
|
Enable Add the following line to Refer to Logging. |
Killing All Executors on Node — killExecutorsOnHost Method
|
Caution
|
FIXME |
Making Fake Resource Offers on Executors — makeOffers Internal Methods
makeOffers(): Unit
makeOffers(executorId: String): UnitmakeOffers takes the active executors (out of the executorDataMap internal registry) and creates WorkerOffer resource offers for each (one per executor with the executor’s id, host and free cores).
|
Caution
|
Only free cores are considered in making offers. Memory is not! Why?! |
It then requests TaskSchedulerImpl to process the resource offers to create a collection of TaskDescription collections that it in turn uses to launch tasks.
Creating CoarseGrainedSchedulerBackend Instance
CoarseGrainedSchedulerBackend takes the following when created:
CoarseGrainedSchedulerBackend initializes the internal registries and counters.
Getting Executor Ids — getExecutorIds Method
When called, getExecutorIds simply returns executor ids from the internal executorDataMap registry.
|
Note
|
It is called when SparkContext calculates executor ids. |
CoarseGrainedSchedulerBackend Contract
class CoarseGrainedSchedulerBackend {
def minRegisteredRatio: Double
def createDriverEndpoint(properties: Seq[(String, String)]): DriverEndpoint
def reset(): Unit
def sufficientResourcesRegistered(): Boolean
def doRequestTotalExecutors(requestedTotal: Int): Future[Boolean]
def doKillExecutors(executorIds: Seq[String]): Future[Boolean]
}|
Note
|
CoarseGrainedSchedulerBackend is a private[spark] contract.
|
| Method | Description |
|---|---|
Ratio between Controlled by spark.scheduler.minRegisteredResourcesRatio. |
|
Always positive, i.e. Used when |
numExistingExecutors Method
|
Caution
|
FIXME |
killExecutors Methods
|
Caution
|
FIXME |
getDriverLogUrls Method
|
Caution
|
FIXME |
applicationAttemptId Method
|
Caution
|
FIXME |
Requesting Additional Executors — requestExecutors Method
requestExecutors(numAdditionalExecutors: Int): BooleanrequestExecutors is a "decorator" method that ultimately calls a cluster-specific doRequestTotalExecutors method and returns whether the request was acknowledged or not (it is assumed false by default).
|
Note
|
requestExecutors method is a part of ExecutorAllocationClient Contract that SparkContext uses for requesting additional executors (as a part of a developer API for dynamic allocation of executors).
|
When called, you should see the following INFO message followed by DEBUG message in the logs:
INFO Requesting [numAdditionalExecutors] additional executor(s) from the cluster manager
DEBUG Number of pending executors is now [numPendingExecutors]numPendingExecutors is increased by the input numAdditionalExecutors.
requestExecutors requests executors from a cluster manager (that reflects the current computation needs). The "new executor total" is a sum of the internal numExistingExecutors and numPendingExecutors decreased by the number of executors pending to be removed.
If numAdditionalExecutors is negative, a IllegalArgumentException is thrown:
Attempted to request a negative number of additional executor(s) [numAdditionalExecutors] from the cluster manager. Please specify a positive number!|
Note
|
It is a final method that no other scheduler backends could customize further. |
|
Note
|
The method is a synchronized block that makes multiple concurrent requests be handled in a serial fashion, i.e. one by one. |
Requesting Exact Number of Executors — requestTotalExecutors Method
requestTotalExecutors(
numExecutors: Int,
localityAwareTasks: Int,
hostToLocalTaskCount: Map[String, Int]): BooleanrequestTotalExecutors is a "decorator" method that ultimately calls a cluster-specific doRequestTotalExecutors method and returns whether the request was acknowledged or not (it is assumed false by default).
|
Note
|
requestTotalExecutors is a part of ExecutorAllocationClient Contract that SparkContext uses for requesting the exact number of executors.
|
It sets the internal localityAwareTasks and hostToLocalTaskCount registries. It then calculates the exact number of executors which is the input numExecutors and the executors pending removal decreased by the number of already-assigned executors.
If numExecutors is negative, a IllegalArgumentException is thrown:
Attempted to request a negative number of executor(s) [numExecutors] from the cluster manager. Please specify a positive number!|
Note
|
It is a final method that no other scheduler backends could customize further. |
|
Note
|
The method is a synchronized block that makes multiple concurrent requests be handled in a serial fashion, i.e. one by one. |
Finding Default Level of Parallelism — defaultParallelism Method
defaultParallelism(): Int|
Note
|
defaultParallelism is a part of the SchedulerBackend Contract.
|
defaultParallelism is spark.default.parallelism Spark property if set.
Otherwise, defaultParallelism is the maximum of totalCoreCount or 2.
Killing Task — killTask Method
killTask(taskId: Long, executorId: String, interruptThread: Boolean): Unit|
Note
|
killTask is part of the SchedulerBackend contract.
|
killTask simply sends a KillTask message to driverEndpoint.
|
Caution
|
FIXME Image |
Stopping All Executors — stopExecutors Method
stopExecutors sends a blocking StopExecutors message to driverEndpoint (if already initialized).
|
Note
|
It is called exclusively while CoarseGrainedSchedulerBackend is being stopped.
|
You should see the following INFO message in the logs:
INFO CoarseGrainedSchedulerBackend: Shutting down all executors Reset State — reset Method
reset resets the internal state:
-
Sets numPendingExecutors to 0
-
Clears
executorsPendingToRemove -
Sends a blocking RemoveExecutor message to driverEndpoint for every executor (in the internal
executorDataMap) to inform it aboutSlaveLostwith the message:Stale executor after cluster manager re-registered.
reset is a method that is defined in CoarseGrainedSchedulerBackend, but used and overriden exclusively by YarnSchedulerBackend.
Remove Executor — removeExecutor Method
removeExecutor(executorId: String, reason: ExecutorLossReason)removeExecutor sends a blocking RemoveExecutor message to driverEndpoint.
|
Note
|
It is called by subclasses SparkDeploySchedulerBackend, CoarseMesosSchedulerBackend, and YarnSchedulerBackend. |
CoarseGrainedScheduler RPC Endpoint — driverEndpoint
When CoarseGrainedSchedulerBackend starts, it registers CoarseGrainedScheduler RPC endpoint to be the driver’s communication endpoint.
driverEndpoint is a DriverEndpoint.
|
Note
|
CoarseGrainedSchedulerBackend is created while SparkContext is being created that in turn lives inside a Spark driver. That explains the name driverEndpoint (at least partially).
|
It is called standalone scheduler’s driver endpoint internally.
It tracks:
It uses driver-revive-thread daemon single-thread thread pool for …FIXME
|
Caution
|
FIXME A potential issue with driverEndpoint.asInstanceOf[NettyRpcEndpointRef].toURI - doubles spark:// prefix.
|
Starting CoarseGrainedSchedulerBackend (and Registering CoarseGrainedScheduler RPC Endpoint) — start Method
start(): Unit|
Note
|
start is a part of the SchedulerBackend contract.
|
start takes all spark.-prefixed properties and registers the CoarseGrainedScheduler RPC endpoint (backed by DriverEndpoint ThreadSafeRpcEndpoint).

Figure 1. CoarseGrainedScheduler Endpoint
|
Note
|
start uses TaskSchedulerImpl to access the current SparkContext and in turn SparkConf.
|
|
Note
|
start uses RpcEnv that was given when CoarseGrainedSchedulerBackend was created.
|
Checking If Sufficient Compute Resources Available Or Waiting Time Passed — isReady Method
isReady(): Boolean|
Note
|
isReady is a part of the SchedulerBackend contract.
|
isReady allows to delay task launching until sufficient resources are available or spark.scheduler.maxRegisteredResourcesWaitingTime passes.
Internally, isReady checks whether there are sufficient resources available.
|
Note
|
sufficientResourcesRegistered by default responds that sufficient resources are available. |
If the resources are available, you should see the following INFO message in the logs and isReady is positive.
INFO SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: [minRegisteredRatio]
|
Note
|
minRegisteredRatio is in the range 0 to 1 (uses spark.scheduler.minRegisteredResourcesRatio) to denote the minimum ratio of registered resources to total expected resources before submitting tasks. |
If there are no sufficient resources available yet (the above requirement does not hold), isReady checks whether the time since startup passed spark.scheduler.maxRegisteredResourcesWaitingTime to give a way to launch tasks (even when minRegisteredRatio not being reached yet).
You should see the following INFO message in the logs and isReady is positive.
INFO SchedulerBackend is ready for scheduling beginning after waiting maxRegisteredResourcesWaitingTime: [maxRegisteredWaitingTimeMs](ms)
Otherwise, when no sufficient resources are available and spark.scheduler.maxRegisteredResourcesWaitingTime has not elapsed, isReady is negative.
Reviving Resource Offers (by Posting ReviveOffers to CoarseGrainedSchedulerBackend RPC Endpoint) — reviveOffers Method
reviveOffers(): Unit|
Note
|
reviveOffers is a part of the SchedulerBackend contract.
|
reviveOffers simply sends a ReviveOffers message to CoarseGrainedSchedulerBackend RPC endpoint.
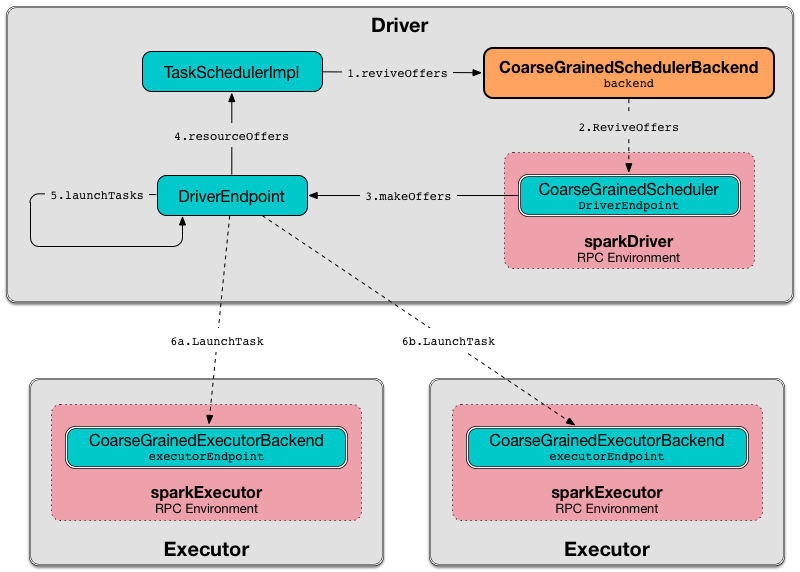
Figure 2. CoarseGrainedExecutorBackend Revives Offers
Stopping CoarseGrainedSchedulerBackend (and Stopping Executors) — stop Method
stop(): Unit|
Note
|
stop is a part of the SchedulerBackend contract.
|
stop stops all executors and CoarseGrainedScheduler RPC endpoint (by sending a blocking StopDriver message).
In case of any Exception, stop reports a SparkException with the message:
Error stopping standalone scheduler's driver endpoint createDriverEndpointRef Method
createDriverEndpointRef(properties: ArrayBuffer[(String, String)]): RpcEndpointRefcreateDriverEndpointRef creates DriverEndpoint and registers it as CoarseGrainedScheduler.
|
Note
|
createDriverEndpointRef is used when CoarseGrainedSchedulerBackend starts.
|
Creating DriverEndpoint — createDriverEndpoint Method
createDriverEndpoint(properties: Seq[(String, String)]): DriverEndpointcreateDriverEndpoint simply creates a DriverEndpoint.
|
Note
|
The purpose of createDriverEndpoint is to allow YARN to use the custom YarnDriverEndpoint.
|
|
Note
|
createDriverEndpoint is used when CoarseGrainedSchedulerBackend createDriverEndpointRef.
|
Settings
| Property | Default Value | Description |
|---|---|---|
|
Time (in milliseconds) between resource offers revives. |
|
|
Maximum message size to allow in RPC communication. In Generally only applies to map output size (serialized) information sent between executors and the driver. Increase this if you are running jobs with many thousands of map and reduce tasks and see messages about the RPC message size. |
|
|
Double number between 0 and 1 (including) that controls the minimum ratio of (registered resources / total expected resources) before submitting tasks. See isReady in this document. |
|
|
Time to wait for sufficient resources available. See isReady in this document. |