TaskScheduler — Spark Scheduler
TaskScheduler is responsible for submitting tasks for execution in a Spark application (per scheduling policy).
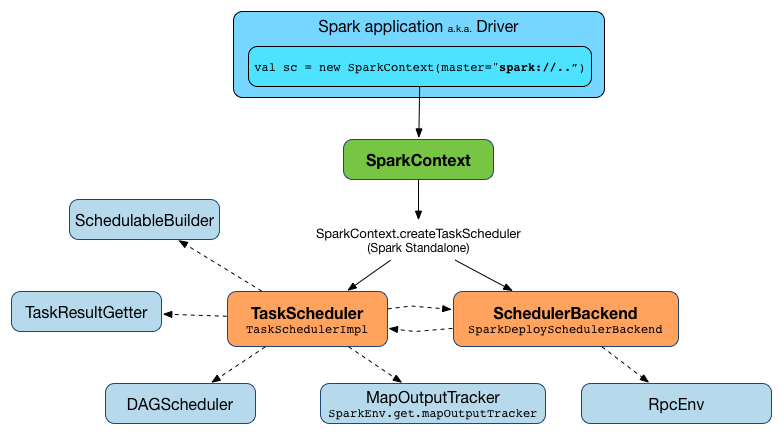
Figure 1. TaskScheduler works for a single SparkContext
|
Note
|
TaskScheduler works closely with DAGScheduler that submits sets of tasks for execution (for every stage in a Spark job).
|
TaskScheduler tracks the executors in a Spark application using executorHeartbeatReceived and executorLost methods that are to inform about active and lost executors, respectively.
Spark comes with the following custom TaskSchedulers:
-
TaskSchedulerImpl — the default
TaskScheduler(that the following two YARN-specificTaskSchedulersextend). -
YarnScheduler for Spark on YARN in client deploy mode.
-
YarnClusterScheduler for Spark on YARN in cluster deploy mode.
|
Note
|
The source of TaskScheduler is available in org.apache.spark.scheduler.TaskScheduler.
|
TaskScheduler Contract
trait TaskScheduler {
def applicationAttemptId(): Option[String]
def applicationId(): String
def cancelTasks(stageId: Int, interruptThread: Boolean): Unit
def defaultParallelism(): Int
def executorHeartbeatReceived(
execId: String,
accumUpdates: Array[(Long, Seq[AccumulatorV2[_, _]])],
blockManagerId: BlockManagerId): Boolean
def executorLost(executorId: String, reason: ExecutorLossReason): Unit
def postStartHook(): Unit
def rootPool: Pool
def schedulingMode: SchedulingMode
def setDAGScheduler(dagScheduler: DAGScheduler): Unit
def start(): Unit
def stop(): Unit
def submitTasks(taskSet: TaskSet): Unit
}|
Note
|
TaskScheduler is a private[spark] contract.
|
| Method | Description |
|---|---|
Unique identifier of an (execution) attempt of a Spark application. Used exclusively when |
|
Unique identifier of a Spark application. By default, it is in the format Used exclusively when |
|
Cancels all tasks of a given stage. Used exclusively when |
|
Calculates the default level of parallelism. Used when |
|
Intercepts heartbeats (with task metrics) from executors. Expected to return Used exclusively when |
|
Intercepts events about executors getting lost. Used when |
|
Post-start initialization. Does nothing by default, but allows custom implementations for some additional post-start initialization. Used exclusively when |
|
Pool (of Schedulables). |
|
Scheduling mode. Puts tasks in order according to a scheduling policy (as |
|
Assigns DAGScheduler. Used exclusively when |
|
Starts Used exclusively when |
|
Stops Used exclusively when |
|
Submits tasks for execution (as TaskSet) of a given stage. Used exclusively when |
TaskScheduler’s Lifecycle
A TaskScheduler is created while SparkContext is being created (by calling SparkContext.createTaskScheduler for a given master URL and deploy mode).
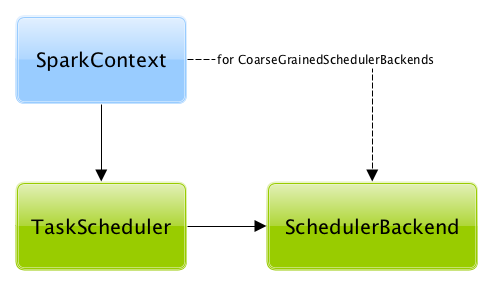
Figure 2. TaskScheduler uses SchedulerBackend to support different clusters
At this point in SparkContext’s lifecycle, the internal _taskScheduler points at the TaskScheduler (and it is "announced" by sending a blocking TaskSchedulerIsSet message to HeartbeatReceiver RPC endpoint).
The TaskScheduler is started right after the blocking TaskSchedulerIsSet message receives a response.
The application ID and the application’s attempt ID are set at this point (and SparkContext uses the application id to set spark.app.id Spark property, and configure SparkUI, and BlockManager).
|
Caution
|
FIXME The application id is described as "associated with the job." in TaskScheduler, but I think it is "associated with the application" and you can have many jobs per application. |
Right before SparkContext is fully initialized, TaskScheduler.postStartHook is called.
The internal _taskScheduler is cleared (i.e. set to null) while SparkContext is being stopped.
|
Warning
|
FIXME If it is SparkContext to start a TaskScheduler, shouldn’t SparkContext stop it too? Why is this the way it is now? |