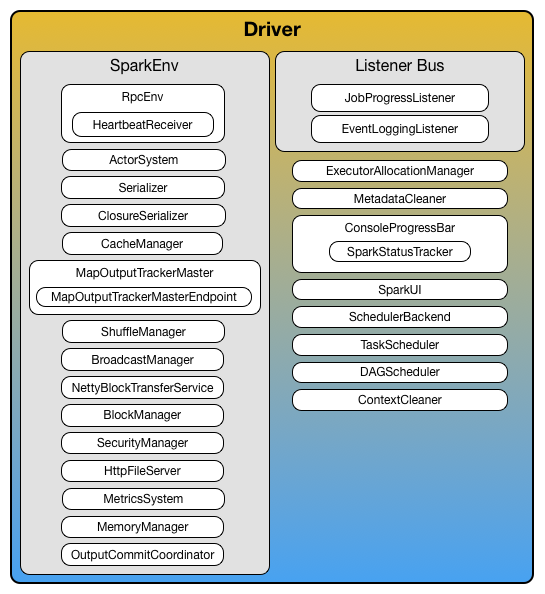
Driver
A Spark driver (aka an application’s driver process) is a JVM process that hosts SparkContext for a Spark application. It is the master node in a Spark application.
It is the cockpit of jobs and tasks execution (using DAGScheduler and Task Scheduler). It hosts Web UI for the environment.
Figure 1. Driver with the services
It splits a Spark application into tasks and schedules them to run on executors.
A driver is where the task scheduler lives and spawns tasks across workers.
A driver coordinates workers and overall execution of tasks.
|
Note
|
Spark shell is a Spark application and the driver. It creates a SparkContext that is available as sc.
|
Driver requires the additional services (beside the common ones like ShuffleManager, MemoryManager, BlockTransferService, BroadcastManager, CacheManager):
-
Listener Bus
-
MapOutputTrackerMaster with the name MapOutputTracker
-
BlockManagerMaster with the name BlockManagerMaster
-
MetricsSystem with the name driver
-
OutputCommitCoordinator with the endpoint’s name OutputCommitCoordinator
|
Caution
|
FIXME Diagram of RpcEnv for a driver (and later executors). Perhaps it should be in the notes about RpcEnv? |
-
High-level control flow of work
-
Your Spark application runs as long as the Spark driver.
-
Once the driver terminates, so does your Spark application.
-
-
Creates
SparkContext, `RDD’s, and executes transformations and actions -
Launches tasks
Driver’s Memory
It can be set first using spark-submit’s --driver-memory command-line option or spark.driver.memory and falls back to SPARK_DRIVER_MEMORY if not set earlier.
|
Note
|
It is printed out to the standard error output in spark-submit’s verbose mode. |
Driver’s Cores
It can be set first using spark-submit’s --driver-cores command-line option for cluster deploy mode.
|
Note
|
In client deploy mode the driver’s memory corresponds to the memory of the JVM process the Spark application runs on.
|
|
Note
|
It is printed out to the standard error output in spark-submit’s verbose mode. |
Settings
| Spark Property | Default Value | Description |
|---|---|---|
Port to use for the BlockManager on the driver. More precisely, |
||
The address of the node where the driver runs on. Set when |
||
|
The port the driver listens to. It is first set to Set to the port of RpcEnv of the driver (in SparkEnv.create) or when client-mode |
|
|
The driver’s memory size (in MiBs). Refer to Driver’s Memory. |
|
|
The number of CPU cores assigned to the driver in cluster deploy mode. NOTE: When Client is created (for Spark on YARN in cluster mode only), it sets the number of cores for Refer to Driver’s Cores. |
|
Additional JVM options for the driver. |
||
|
spark.driver.extraClassPath
spark.driver.extraClassPath system property sets the additional classpath entries (e.g. jars and directories) that should be added to the driver’s classpath in cluster deploy mode.
|
Note
|
For Do not use SparkConf since it is too late for Refer to |
spark.driver.extraClassPath uses a OS-specific path separator.
|
Note
|
Use spark-submit's --driver-class-path command-line option on command line to override spark.driver.extraClassPath from a Spark properties file.
|