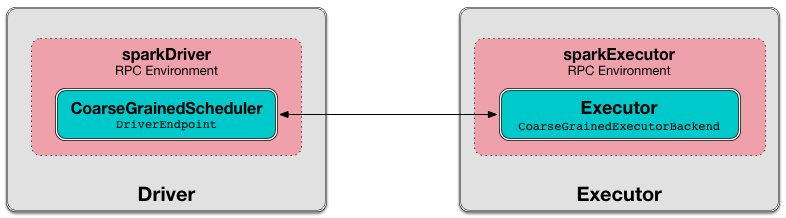
DriverEndpoint — CoarseGrainedSchedulerBackend RPC Endpoint
DriverEndpoint is a ThreadSafeRpcEndpoint that acts as a message handler for CoarseGrainedSchedulerBackend to communicate with CoarseGrainedExecutorBackend.
Figure 1. CoarseGrainedSchedulerBackend uses DriverEndpoint for communication with CoarseGrainedExecutorBackend
DriverEndpoint is created when CoarseGrainedSchedulerBackend starts.
DriverEndpoint uses executorDataMap internal registry of all the executors that registered with the driver. An executor sends a RegisterExecutor message to inform that it wants to register.
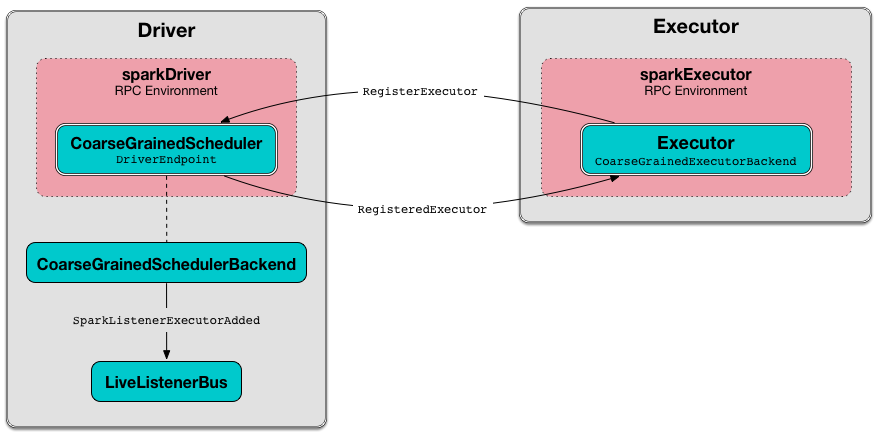
Figure 2. Executor registration (RegisterExecutor RPC message flow)
DriverEndpoint uses a single thread executor called driver-revive-thread to make executor resource offers (for launching tasks) (by emitting ReviveOffers message every spark.scheduler.revive.interval).
| CoarseGrainedClusterMessage | Event Handler | When emitted? |
|---|---|---|
|
||
|
||
|
||
|
||
|
| Name | Initial Value | Description |
|---|---|---|
Executor addresses (host and port) for executors. Set when an executor connects to register itself. See RegisterExecutor RPC message. |
||
disableExecutor Internal Method
|
Caution
|
FIXME |
KillExecutorsOnHost Handler
|
Caution
|
FIXME |
executorIsAlive Internal Method
|
Caution
|
FIXME |
onStop Callback
|
Caution
|
FIXME |
onDisconnected Callback
When called, onDisconnected removes the worker from the internal addressToExecutorId registry (that effectively removes the worker from a cluster).
While removing, it calls removeExecutor with the reason being SlaveLost and message:
Remote RPC client disassociated. Likely due to containers exceeding thresholds, or network issues. Check driver logs for WARN messages.
|
Note
|
onDisconnected is called when a remote host is lost.
|
StopExecutors
StopExecutors message is receive-reply and blocking. When received, the following INFO message appears in the logs:
INFO Asking each executor to shut downIt then sends a StopExecutor message to every registered executor (from executorDataMap).
Scheduling Sending ReviveOffers Periodically — onStart Callback
onStart(): Unit|
Note
|
onStart is a part of RpcEndpoint contract that is executed before a RPC endpoint starts accepting messages.
|
onStart schedules a periodic action to send ReviveOffers immediately every spark.scheduler.revive.interval.
|
Note
|
spark.scheduler.revive.interval defaults to 1s.
|
Making Executor Resource Offers (for Launching Tasks) — makeOffers Internal Method
makeOffers(): UnitmakeOffers first creates WorkerOffers for all active executors (registered in the internal executorDataMap cache).
|
Note
|
WorkerOffer represents a resource offer with CPU cores available on an executor.
|
makeOffers then requests TaskSchedulerImpl to generate tasks for the available WorkerOffers followed by launching the tasks on respective executors.
|
Note
|
makeOffers uses TaskSchedulerImpl that was given when CoarseGrainedSchedulerBackend was created.
|
|
Note
|
Tasks are described using TaskDescription that holds…FIXME |
|
Note
|
makeOffers is used when CoarseGrainedSchedulerBackend RPC endpoint (DriverEndpoint) handles ReviveOffers or RegisterExecutor messages.
|
Making Executor Resource Offer on Single Executor (for Launching Tasks) — makeOffers Internal Method
makeOffers(executorId: String): UnitmakeOffers makes sure that the input executorId is alive.
|
Note
|
makeOffers does nothing when the input executorId is registered as pending to be removed or got lost.
|
makeOffers finds the executor data (in executorDataMap registry) and creates a WorkerOffer.
|
Note
|
WorkerOffer represents a resource offer with CPU cores available on an executor.
|
makeOffers then requests TaskSchedulerImpl to generate tasks for the WorkerOffer followed by launching the tasks (on the executor).
|
Note
|
makeOffers is used when CoarseGrainedSchedulerBackend RPC endpoint (DriverEndpoint) handles StatusUpdate messages.
|
Launching Tasks on Executors — launchTasks Method
launchTasks(tasks: Seq[Seq[TaskDescription]]): UnitlaunchTasks flattens (and hence "destroys" the structure of) the input tasks collection and takes one task at a time. Tasks are described using TaskDescription.
|
Note
|
The input tasks collection contains one or more TaskDescriptions per executor (and the "task partitioning" per executor is of no use in launchTasks so it simply flattens the input data structure).
|
launchTasks encodes the TaskDescription and makes sure that the encoded task’s size is below the maximum RPC message size.
|
Note
|
The maximum RPC message size is calculated when CoarseGrainedSchedulerBackend is created and corresponds to spark.rpc.message.maxSize Spark property (with maximum of 2047 MB).
|
If the size of the encoded task is acceptable, launchTasks finds the ExecutorData of the executor that has been assigned to execute the task (in executorDataMap internal registry) and decreases the executor’s available number of cores.
|
Note
|
ExecutorData tracks the number of free cores of an executor (as freeCores).
|
|
Note
|
The default task scheduler in Spark — TaskSchedulerImpl — uses spark.task.cpus Spark property to control the number of tasks that can be scheduled per executor. |
You should see the following DEBUG message in the logs:
DEBUG DriverEndpoint: Launching task [taskId] on executor id: [executorId] hostname: [executorHost].In the end, launchTasks sends the (serialized) task to associated executor to launch the task (by sending a LaunchTask message to the executor’s RPC endpoint with the serialized task insize SerializableBuffer).
|
Note
|
ExecutorData tracks the RpcEndpointRef of executors to send serialized tasks to (as executorEndpoint).
|
|
Important
|
This is the moment in a task’s lifecycle when the driver sends the serialized task to an assigned executor. |
In case the size of a serialized TaskDescription equals or exceeds the maximum RPC message size, launchTasks finds the TaskSetManager (associated with the TaskDescription) and aborts it with the following message:
Serialized task [id]:[index] was [limit] bytes, which exceeds max allowed: spark.rpc.message.maxSize ([maxRpcMessageSize] bytes). Consider increasing spark.rpc.message.maxSize or using broadcast variables for large values.
|
Note
|
launchTasks uses the registry of active TaskSetManagers per task id from TaskSchedulerImpl that was given when CoarseGrainedSchedulerBackend was created.
|
|
Note
|
Scheduling in Spark relies on cores only (not memory), i.e. the number of tasks Spark can run on an executor is limited by the number of cores available only. When submitting a Spark application for execution both executor resources — memory and cores — can however be specified explicitly. It is the job of a cluster manager to monitor the memory and take action when its use exceeds what was assigned. |
Creating DriverEndpoint Instance
DriverEndpoint takes the following when created:
DriverEndpoint initializes the internal registries and counters.
RegisterExecutor Handler
RegisterExecutor(
executorId: String,
executorRef: RpcEndpointRef,
hostname: String,
cores: Int,
logUrls: Map[String, String])
extends CoarseGrainedClusterMessage|
Note
|
RegisterExecutor is sent when CoarseGrainedExecutorBackend (RPC Endpoint) is started.
|
Figure 3. Executor registration (RegisterExecutor RPC message flow)
When received, DriverEndpoint makes sure that no other executors were registered under the input executorId and that the input hostname is not blacklisted.
|
Note
|
DriverEndpoint uses TaskSchedulerImpl (for the list of blacklisted nodes) that was specified when CoarseGrainedSchedulerBackend was created.
|
If the requirements hold, you should see the following INFO message in the logs:
INFO Registered executor [executorRef] ([address]) with ID [executorId]DriverEndpoint does the bookkeeping:
-
Registers
executorId(in addressToExecutorId) -
Adds
cores(in totalCoreCount) -
Increments totalRegisteredExecutors
-
Creates and registers
ExecutorDataforexecutorId(in executorDataMap) -
Updates currentExecutorIdCounter if the input
executorIdis greater than the current value.
If numPendingExecutors is greater than 0, you should see the following DEBUG message in the logs and DriverEndpoint decrements numPendingExecutors.
DEBUG Decremented number of pending executors ([numPendingExecutors] left)DriverEndpoint sends RegisteredExecutor message back (that is to confirm that the executor was registered successfully).
|
Note
|
DriverEndpoint uses the input executorRef as the executor’s RpcEndpointRef.
|
DriverEndpoint replies true (to acknowledge the message).
DriverEndpoint then announces the new executor by posting SparkListenerExecutorAdded to LiveListenerBus (with the current time, executor id, and ExecutorData).
In the end, DriverEndpoint makes executor resource offers (for launching tasks).
If however there was already another executor registered under the input executorId, DriverEndpoint sends RegisterExecutorFailed message back with the reason:
Duplicate executor ID: [executorId]If however the input hostname is blacklisted, you should see the following INFO message in the logs:
INFO Rejecting [executorId] as it has been blacklisted.DriverEndpoint sends RegisterExecutorFailed message back with the reason:
Executor is blacklisted: [executorId]StatusUpdate Handler
StatusUpdate(
executorId: String,
taskId: Long,
state: TaskState,
data: SerializableBuffer)
extends CoarseGrainedClusterMessage|
Note
|
StatusUpdate is sent when CoarseGrainedExecutorBackend sends task status updates to the driver.
|
When StatusUpdate is received, DriverEndpoint passes the task’s status update to TaskSchedulerImpl.
|
Note
|
TaskSchedulerImpl is specified when CoarseGrainedSchedulerBackend is created.
|
If the task has finished, DriverEndpoint updates the number of cores available for work on the corresponding executor (registered in executorDataMap).
|
Note
|
DriverEndpoint uses TaskSchedulerImpl's spark.task.cpus as the number of cores that became available after the task has finished.
|
DriverEndpoint makes an executor resource offer on the single executor.
When DriverEndpoint found no executor (in executorDataMap), you should see the following WARN message in the logs:
WARN Ignored task status update ([taskId] state [state]) from unknown executor with ID [executorId]KillTask Handler
KillTask(
taskId: Long,
executor: String,
interruptThread: Boolean)
extends CoarseGrainedClusterMessage|
Note
|
KillTask is sent when CoarseGrainedSchedulerBackend kills a task.
|
When KillTask is received, DriverEndpoint finds executor (in executorDataMap registry).
If found, DriverEndpoint passes the message on to the executor (using its registered RPC endpoint for CoarseGrainedExecutorBackend).
Otherwise, you should see the following WARN in the logs:
WARN Attempted to kill task [taskId] for unknown executor [executor]. Removing Executor from Internal Registries (and Notifying TaskSchedulerImpl and Posting SparkListenerExecutorRemoved) — removeExecutor Internal Method
removeExecutor(executorId: String, reason: ExecutorLossReason): UnitWhen removeExecutor is executed, you should see the following DEBUG message in the logs:
DEBUG Asked to remove executor [executorId] with reason [reason]removeExecutor then tries to find the executorId executor (in executorDataMap internal registry).
If the executorId executor was found, removeExecutor removes the executor from the following registries:
removeExecutor decrements:
-
totalCoreCount by the executor’s
totalCores
In the end, removeExecutor notifies TaskSchedulerImpl that an executor was lost.
|
Note
|
removeExecutor uses TaskSchedulerImpl that is specified when CoarseGrainedSchedulerBackend is created.
|
removeExecutor posts SparkListenerExecutorRemoved to LiveListenerBus (with the executorId executor).
If however the executorId executor could not be found, removeExecutor requests BlockManagerMaster to remove the executor asynchronously.
|
Note
|
removeExecutor uses SparkEnv to access the current BlockManager and then BlockManagerMaster.
|
You should see the following INFO message in the logs:
INFO Asked to remove non-existent executor [executorId]|
Note
|
removeExecutor is used when DriverEndpoint handles RemoveExecutor message and gets disassociated with a remote RPC endpoint of an executor.
|