spark-submit --master yarn mySparkApp.jarSpark on YARN
You can submit Spark applications to a Hadoop YARN cluster using yarn master URL.
|
Note
|
Since Spark 2.0.0, yarn master URL is the only proper master URL and you can use --deploy-mode to choose between client (default) or cluster modes.
|
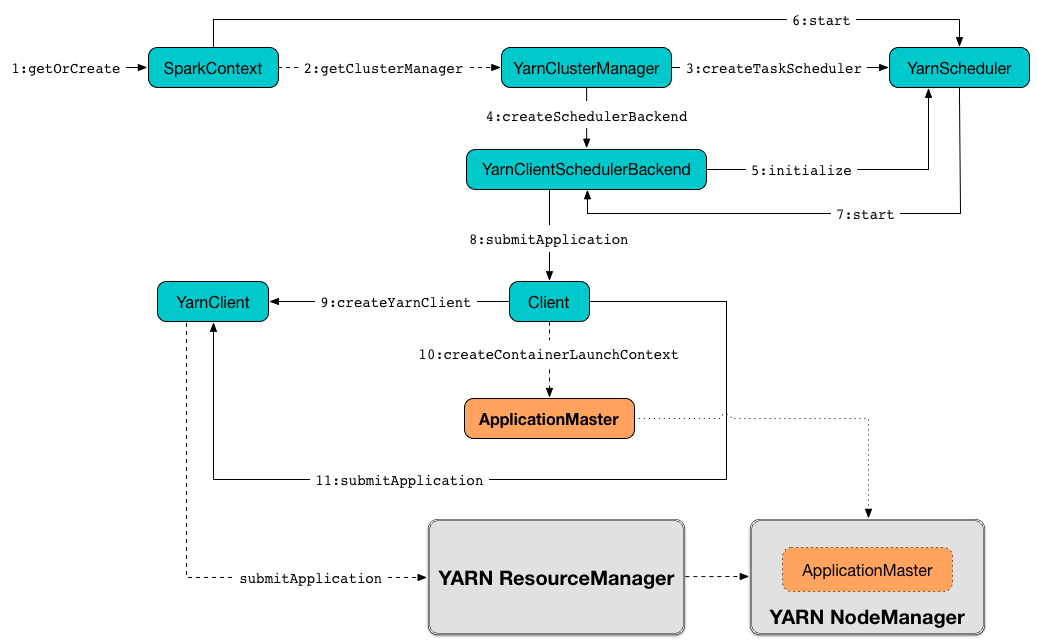
Figure 1. Submitting Spark Application to YARN Cluster (aka Creating SparkContext with yarn Master URL and client Deploy Mode)
Without specifying the deploy mode, it is assumed client.
spark-submit --master yarn --deploy-mode client mySparkApp.jar|
Tip
|
Deploy modes are all about where the Spark driver runs. |
In client mode the Spark driver (and SparkContext) runs on a client node outside a YARN cluster whereas in cluster mode it runs inside a YARN cluster, i.e. inside a YARN container alongside ApplicationMaster (that acts as the Spark application in YARN).
spark-submit --master yarn --deploy-mode cluster mySparkApp.jarIn that sense, a Spark application deployed to YARN is a YARN-compatible execution framework that can be deployed to a YARN cluster (alongside other Hadoop workloads). On YARN, a Spark executor maps to a single YARN container.
|
Note
|
In order to deploy applications to YARN clusters, you need to use Spark with YARN support. |
Spark on YARN supports multiple application attempts and supports data locality for data in HDFS. You can also take advantage of Hadoop’s security and run Spark in a secure Hadoop environment using Kerberos authentication (aka Kerberized clusters).
There are few settings that are specific to YARN (see Settings). Among them, you can particularly like the support for YARN resource queues (to divide cluster resources and allocate shares to different teams and users based on advanced policies).
|
Tip
|
You can start spark-submit with --verbose command-line option to have some settings displayed, including YARN-specific. See spark-submit and YARN options.
|
The memory in the YARN resource requests is --executor-memory + what’s set for spark.yarn.executor.memoryOverhead, which defaults to 10% of --executor-memory.
If YARN has enough resources it will deploy the executors distributed across the cluster, then each of them will try to process the data locally (NODE_LOCAL in Spark Web UI), with as many splits in parallel as you defined in spark.executor.cores.
Multiple Application Attempts
Spark on YARN supports multiple application attempts in cluster mode.
|
Caution
|
FIXME |
spark-submit and YARN options
When you submit your Spark applications using spark-submit you can use the following YARN-specific command-line options:
-
--archives -
--executor-cores -
--keytab -
--num-executors -
--principal
|
Tip
|
Read about the corresponding settings in Settings in this document. |
Memory Requirements
When Client submits a Spark application to a YARN cluster, it makes sure that the application will not request more than the maximum memory capability of the YARN cluster.
The memory for ApplicationMaster is controlled by custom settings per deploy mode.
For client deploy mode it is a sum of spark.yarn.am.memory (default: 512m) with an optional overhead as spark.yarn.am.memoryOverhead.
For cluster deploy mode it is a sum of spark.driver.memory (default: 1g) with an optional overhead as spark.yarn.driver.memoryOverhead.
If the optional overhead is not set, it is computed as 10% of the main memory (spark.yarn.am.memory for client mode or spark.driver.memory for cluster mode) or 384m whatever is larger.
Spark with YARN support
You need to have Spark that has been compiled with YARN support, i.e. the class org.apache.spark.deploy.yarn.Client must be on the CLASSPATH.
Otherwise, you will see the following error in the logs and Spark will exit.
Error: Could not load YARN classes. This copy of Spark may not have been compiled with YARN support.Master URL
Since Spark 2.0.0, the only proper master URL is yarn.
./bin/spark-submit --master yarn ...Before Spark 2.0.0, you could have used yarn-client or yarn-cluster, but it is now deprecated. When you use the deprecated master URLs, you should see the following warning in the logs:
Warning: Master yarn-client is deprecated since 2.0. Please use master "yarn" with specified deploy mode instead.Keytab
|
Caution
|
FIXME |
When a principal is specified a keytab must be specified, too.
The settings spark.yarn.principal and spark.yarn.principal will be set to respective values and UserGroupInformation.loginUserFromKeytab will be called with their values as input arguments.
Environment Variables
SPARK_DIST_CLASSPATH
SPARK_DIST_CLASSPATH is a distribution-defined CLASSPATH to add to processes.
It is used to populate CLASSPATH for ApplicationMaster and executors.
Settings
|
Caution
|
FIXME Where and how are they used? |
Further reading or watching
-
(video) Spark on YARN: The Road Ahead — Marcelo Vanzin (Cloudera) from Spark Summit 2015